-
5. FFNN(Feed Forward Neutral Network)general ML, DL, NLP/딥러닝 2022. 4. 20. 13:55
*본 게시물은 22-1학기 연세대학교 일반대학원 딥러닝을이용한비정형데이터분석(이상엽 교수님) 수업 내용을 정리한 것입니다.
FFNN(Feed Forward Neural Network)
FFNN이란 기본적인 신경망을 뜻합니다. 그동안 정리해왔던 신경망이 바로 FFNN입니다.
FFNN은 FNN, ANN(Artificial Neural Network), MLP(Multilayer Perceptron), 혹은 Dense layer 등등으로 불리기도 합니다.
앞서 이야기했던 것처럼 은닉층이 2개 이상인 것부터 deep 자가 붙습니다.

deep 자가 붙을 수 있는 신경망입니다 ㅋㅋ 데이터에 신경망을 적용하고자 할 경우 정해야 하는 순서는 다음과 같습니다.
* 데이터에 신경망을 적용한다는 것은 곧 학습 데이터에 신경망 모형을 적용하여 학습을 시작한다는 것을 의미합니다.
1. 연구문제 설정
2. 데이터셋 결정
3. 수학적 모형 결정
4. 모형 구조 결정일단 1. '조건에 따른 집값 예측'을 연구 문제로 잡았을 경우, 2. Boston housing price 데이터셋을 사용할 수 있습니다.
이후 3. 신경망을 쓰기로 결정했다면, 4. 모형의 구조를 결정해야 합니다.
신경망의 모형 구조 결정은 보통 ① 입력층 & 출력층 노드 갯수 결정, ② 은닉층 & 은닉노드 개수 결정으로 이루어집니다. ①의 경우 풀고자 하는 연구 문제와 데이터셋, ②는 사용자 마음대로(하이퍼파라미터) 결정됩니다.
1. FFNN을 활용한 회귀문제
수업 시간에는 FFNN을 활용한 회귀문제를 다뤘었습니다. 데이터셋은 Boston housing price 예측입니다.
사용 프레임워크는 Keras입니다.
1) 우선은 데이터를 로드합니다.
Boston housing price 예측은 tensorflow 자체에서 불러올 수 있습니다.
(*keras.datasets에 있는 데이터만 불러올 수 있습니다!ㅋㅋㅋ 임의의 데이터는 따로 변수에 저장하는 과정을 거치셔야 합니다.)
12345import tensorflow as tffrom tensorflow import keras# 데이터(train_data, train_targets), (test_data, test_targets) =keras.datasets.boston_housing.load_data()cs 2) 데이터를 불러왔으니 데이터 모양을 봐야겠죠. 데이터를 살펴봅니다.
123456789train_data.shape # train_data.shape[1]은 곧 13이 됨(입력노드의 수)# (404, 13) # 404개의 관측치, 13개의 독립변수train_targets.shape # (404,)# 독립변수: 집값에 영향을 미치는 13개의 변수(범죄율, 교통 편의성...)train_data[0] # array([ 1.23247, 0., 8.14, 0., 0.538, 6.142, 91.7 , 3.9769, 4., 307., 21., 396.9,18.72])# 종속변수: 미국 Boston에 속한 도시들의 70년대 중반 집 가격의 중간값train_targets[:5] # array([15.2, 42.3, 50. , 21.1, 17.7])cs 일단 훈련 데이터의 모양(train_data.shape)은 (404, 13)입니다. 이는 훈련 데이터에 있는 관측치가 총 404개, 13개의 독립변수가 있다는 뜻입니다. 즉 404개의 행, 13개의 열이 있는 엑셀 시트를 상상하시면 되겠습니다.
집값을 맞추는 문제이므로 훈련 데이터의 답(train_targets)은 당연히 404개 관측치에 대한 404개의 집값이 됩니다~
실제로 train_data의 첫 번째(인덱스 0) 데이터를 살펴보니, 각 13개 독립변수 별로
[ 1.23247, 0., 8.14, 0., 0.538, 6.142, 91.7 , 3.9769, 4., 307., 21., 396.9,18.72 ] 와 같은 값들이 있는 것이 확인됩니다.
train_targets 5개를 살펴보니 첫 번째 관측치의 집값은 15.2, 두 번째 관측치 집값은 42.3... 등 5개 관측치에 대해 상응하는 집값이 확인됩니다 :D
3) 이제 본격적으로 신경망을 쌓겠습니다.
(주요 하이퍼파라미터: 은닉 노드 수, 활성화 함수)
123456789101112131415161718192021222324# 두 개의 모듈 임포트: models, layersfrom tensorflow.keras import modelsfrom tensorflow.keras import layers # layers 모듈 안에는 각 층을 나타내는 Dense 클래스가 저장# 다시금 shape 확인train_data.shape # (404, 13)train_data.shape[1] # (404,13) 중 13 (=입력노드의 수)# 사용하고자 하는 신경망 구축하기model = models.Sequential() # 입력층을 별도로 추가하지 않는다!model.add(layers.Dense(64, activation = 'relu', input_shape=(train_data.shape[1],))) # 첫번쨰 은닉층: 입력노드의 개수로 입력받아야 함# 입력노드 개수로 받기 위해 input_shape=(train_data.shape[1]를 밝혀줍니다.model.add(layers.Dense(64, activation = 'relu')) # 두 번째 은닉층, 64개 노드가 있습니다.model.add(layers.Dense(1)) # 회귀이므로 출력노드는 1개입니다.model.summary()# 첫번 째 은닉층: 은닉 노드 수는 64 , 입력~은닉층1 사이의 파라미터의 수는(14*64)# 두번 째 은닉층: 은닉 노드 수는 64, 은닉층1~은닉층2 간의 파라미터 수는 (65*64)# 두번쨰 은닉층~ 마지막 출력층 사이의 파라미터 수는 (65*1(회귀))# 이 문제를 선형회귀를 가지고 푼다? 파라미터 개수는 14개(입력+편향)# 딥러닝을 쓰는 것이 파라미터 수가 훨씬 더 복잡함cs 일단 신경망을 쌓기 위해서는 Keras에서 models, layers라는 모듈을 불러와야 합니다. 특히 layers 안에는 Dense 클래스가 저장되어 있어, 이 dense 클래스 하나의 객체가 하나의 층이 되어 순서대로 층층이 쌓는 것을 가능하게 합니다.
또한 Keras에서 신경망을 선언하는 것은 model=models.Sequential() 클래스로, 쌓는 것은 model.add 클래스를 통해 매우 간단하게 할 수 있습니다^0^.
Sequential()외에도 functional()이 있다고는 하는데, 좀 더 복잡한 모형에 사용된다고 합니다. :D
신경망은 입력층-은닉층-출력층 구조를 가집니다. 다만 Keras에서는 입력층을 따로 선언하지 않는 대신, 첫번째 은닉층에서 입력 노드의 수를 밝혀줌으로써 이것을 대신하고 있습니다. Keras에서 은닉층은 파라미터 수(노드 수), 활성화 함수 등을 하이퍼파라미터로 넣어줍니다.
아래의 사항은 Dense()라는 생성자 함수 안에 들어가는 하이퍼파라미터들입니다 :D 입력 노드 & 첫 번째 은닉층 입력노드 수: input_shape = (train_data.shape[1],) # 13
은닉층1 은닉노드 수: 64
은닉층1 활성화 함수: relu두 번째 은닉층 은닉층2 은닉노드 수: 64
은닉층2 활성화 함수: relu출력층 회귀이므로 출력노드는 1개 위 코드에 따라 구축한 신경망은 다음과 같습니다.

위 신경망 구조를 보면 파라미터 수를 쉽게 계산할 수 있습니다.
기본 원칙은 한 노드에 들어오는 입력에는 1을 더해서 곱하는 것입니다. 여기서 1은 편향 노드 수입니다.


그림으로 다시한번 정리하면 이런 느낌입니다 4) 쌓았으니 compile해야 합니다.
(주요 하이퍼파라미터: 옵티마이저, loss function(비용함수, 성능평가 metric)
123456# 학습에 사용되는 옵티마이저, 미니배치의 크기, 사용하고자 하는 비용함수# Optimizer 종류 => https://keras.io/api/optimizers/adam = tf.keras.optimizers.Adam(learning_rate=0.01)model.compile(optimizer=adam, loss='mse') # 비용함수 결정cs compile을 하지 않으면 다음 단계인 훈련(.fit())이 되지 않습니다. compile 과정에서는 학습에 쓰이는 옵티마이저와 미니 배치 크기, 비용함수가 하이퍼파라미터입니다. 여기서는 Adam을 옵티마이저로, 회귀니까 MSE를 비용함수로 하고, 성능평가 metric은 지정하지 않았습니다^^;
5) 이제 훈련합니다.
(주요 하이퍼파라미터: 에폭 수, 미니 배치 수)
123history = model.fit(train_data, train_targets, epochs=80, batch_size=20) # fit 펑션으로 학습# 에폭: 전체 학습을 몇 번 할래? 80번# 배치 사이즈: 20, 미니배치 크기를 20으로 해서 볼거야 -한 에폭 당 iteration이 21번 정도 됨cs 훈련은 .fit 함수로 가능합니다. 여기서는 (6)을 위해 훈련 결과를 history라는 변수에 저장해놓았습니다.
훈련 시에는 에폭 수와 배치 사이즈를 결정하게됩니다.
에폭은 전체 학습을 몇 번 할 지 결정하는 하이퍼파라미터입니다. 수가 증가할수록 학습이 잘 되나 지나치게 많이 되면 overfitting이 일어납니다. 배치 사이즈는 mini-batch 수를 결정하는 것입니다. 아까 훈련 데이터 갯수가 404개였으므로, mini-batch를 20으로 한다면 한 에폭 당 약 21번의 가중치 업데이트가 일어납니다.

Epoch 밑에 21/21이 보입니다. 한 epoch을 돌 때 가중치 업데이트가 21번 일어나고 있는 것입니다. 6) 훈련이 끝나면 훈련 결과를 plot으로 확인할 수 있습니다.
이 때 확인해야 할 것은 loss 값이 잘 떨어졌는지입니다. 만일 loss 값이 떨어지지 않고 유지되거나 증가한다면 잘못된 훈련이므로 다시 compile~훈련 과정을 거쳐야 합니다 흑.. 잘 떨어졌는지 보기위해 matplotlib을 사용하여 그림을 그려(plot)보겠습니다.
1234567import matplotlib.pyplot as pltplt.plot(history.history['loss']) # history에 저장된 것 중 loss를 그림plt.xlabel('epoch') # x축 이름plt.ylabel('loss') # y 축 이름plt.legend(['train']) # 선plt.show()cs 위 코드를 실행하면 아래와 같은 아름다운 그림이 나타납니다. loss값이 매우 잘 떨어진 것을 확인할 수 있습니다.

7) 훈련이 정말 잘 되었는지 성능을 평가합니다.
회귀 성능 평가는 R제곱(스퀘어)을 사용합니다. 평가를 위해 sklearn.metrics의 r2_score를 불러옵니다.
1234567891011121314from sklearn.metrics import r2_score# 회귀의 성능은 R제곱을 사용# test_data에 대해 성능 평가하기y_pred = model.predict(test_data) # 훈련된 모델을 통해 test_data를 예측한 후 y_pred 변수에 넣습니다.r2_score(test_targets, y_pred) # 진짜 test_data의 답인 test_targets와 예측값 y_pred를 비교합니다.# 0.5802064689495752# 개별 데이터에 대해서도 예측을 해봅시다.test_data[0] # 첫 번째 테스트 데이터를 불러옵니다. 관측치 13개가 들어있습니다.model.predict(test_data[0:1]) # 관측치에 대해 예측한 집값은 array([[9.538062]] 입니다.#개별 데이터와 진짜 값을 비교합니다.test_targets[0] # 7.2 ^^;cs 평가는 테스트 데이터인 test_data를 model.predict()함수를 통해 이루어집니다. 여기에서는 r2_score 계산을 위해 predict한 결과를 y_pred에 저장했습니다. 이렇게 시행한 예측과 진짜 답(test_targets)을 비교해보니, 0.58 정도의 R제곱 값이 도출됩니다.
위 코드에서 볼 수 있듯이 개별 데이터에 대해서도 예측과 비교가 가능합니다~^^
2. FFNN을 활용한 이미지 분류 문제
딥러닝은 비정형 데이터(이미지, 텍스트, 오디오, 비디오)를 처리하는데 좋습니다. 사람이 독립변수를 추출하지 않아도, 딥러닝 모형이 알아서 종속변수 값을 예측하는 데 중요한 정보를 은닉층에서 추출하기 때문입니다. 이는 비용함수, 경사하강법 등에서 이미 소개했습니다 :D
비용함수의 값을 minimize하는 최적의 파라미터를 찾기 위해 다양한 옵티마이저들이 사용됩니다. 최적의 파라미터란 또 독립변수와 종속변수 간의 관계를 가장 잘 나타내는 파라미터이기도 합니다.
1) 이미지 데이터
이미지는 여러 픽셀로 구성됩니다. 가령 m*n 이미지는 m*n개의 픽셀을 가집니다. 또한 컬러 이미지냐 흑백 이미지냐에 따라 채널(depth) 값이 다릅니다.
(1) 컬러 이미지
컬러 이미지의 경우 보통 3가지 색 정보(RGB)를 지니기 때문에, 컬러 이미지는 3개의 채널(depth로도 불립니다)을 가지며 보통 m*n*3으로 표현됩니다.
당연히 각 픽셀마다도 3개 채널(depth)에 대한 정보를 가지게 됩니다.(빨, 파, 녹의 셀로판지를 겹친 것 같이ㅎ_ㅎ)
이 색상정보는 정도에 따라 0~255까지의 숫자로 표현되며, 각 픽셀은 3가지 채널 정보를 저장하기 위해 3차원 형태의 행렬로 표현됩니다(3D array; tensor)

(2) 흑백 이미지
흑백 이미지는 채널이 1입니다. 때문에 m*n*1로 표현됩니다. 각 픽셀은 0~255사이의 값을 가지며, 255에 가까울수록 흰색, 0에 가까울수록 검은색이 됩니다.

2) FFNN을 활용한 MNIST(흑백이미지) 분류
위에서 신경망을 사용하기 위해서는 입력 노드와 출력 노드, 그리고 은닉층과 은닉 노드의 수를 정해야 한다고 했습니다.
이미지의 경우 입력 노드 수는 m*n*1 또는 m*n*3이 됩니다.
가령 10*10 컬러 이미지의 경우 채널은 3개 있으므로 색상 정보의 수는 총 10*10*3으로 300개가 됩니다. FFNN에서 하나의 색상정보는 하나의 독립 변수(feature)로 간주됩니다. 때문에 입력 노드 수는 300개가 됩니다.
MNIST의 경우 28*28의 흑백 이미지입니다. 때문에 784개의 feature와 동시에 입력 노드가 존재하게 됩니다. 다만 이를 신경망에 넣기 위해서는 마치 가래떡 뽑듯이 reshape()함수로 1차원으로 만들어주어야 합니다^^ 이따 코드에서 설명하겠습니다.
(0) 신경망 구조 정하기
MNIST를 해결하기 위한 신경망 구조는 다음과 같습니다.
입력 노드 수: 784
은닉층 & 은닉 노드 개수: 1층, 512
출력 노드 수: 10 (0~9까지의 라벨)
(1) 데이터셋 불러오기
1234import tensorflow as tffrom tensorflow import kerasimport matplotlib.pyplot as plt(train_images, train_labels), (test_images, test_labels) = keras.datasets.mnist.load_data()cs MNIST 데이터셋 역시 Keras 자체에서 불러올 수 있습니다. 회귀 분석과 마찬가지로 데이터를 불러온 후 훈련 데이터와 훈련 데이터의 라벨, 테스트 데이터와 테스트 데이터의 라벨에 할당합니다.(자기가 알아서 해줍니다 ^^)
(2) 데이터셋 확인
123456789101112131415161718train_images.shape # (60000, 28, 28)# 학습데이터의 이미지 수, 가로픽셀길이, 세로픽셀길이# 훈련 데이터 낱장 확인train_images[59999].shape # (784,)type(train_images[59999]) # numpy.ndarraytrain_images[59999] # 첫번째 이미지, 255에 가까울수록 흰색을 의미# 색상정보(feature value)는 0~255사이의 값을 취함"""...], [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 89, 219,254, 97, 67, 14, 0, 0, 92, 231, 122, 23, 203, 236, 59,...."""# 낱장 이미지plt.imshow(train_images[59999], cmap='gray') # cmap='gray', vmin=0, vmax=255plt.show()train_labels[59999] # 8: 종속변수 확인cs 이제는 훈련 데이터를 확인해보겠습니다.
일단 훈련 데이터의 형태는 (60000, 28, 28)입니다. 이를 통해 훈련 데이터의 전체 개수는 6만개, 생김새는 28*28임을 알 수 있습니다.
60000번째 훈련 데이터를 살펴보니 형태는 (784,)의 np.array 형태입니다. 즉 28*28개 총 784개의 픽셀 값이 np.array 형태로 저장되어 있음을 알 수 있습니다. 실제로 살펴보니 0, 0, 0, ... 254, 97.... 등등이 보입니다.
이 훈련 데이터 낱장을 plot해서 볼 수도 있는데요, plot하면 다음과 같은 그림이 나타납니다.

실제로 이 훈련 데이터의 라벨은(train_labels[59999]) 8입니다. 짱신기해~
(3) 신경망 쌓기
다음은 신경망을 만드는 단계입니다. 회귀문제와 마찬가지로 keras에서 models, layers 모듈을 불러와 쌓습니다.
123456789101112from tensorflow.keras import modelsfrom tensorflow.keras import layersmodel = models.Sequential()model.add(layers.Dense(512, activation = 'relu', input_shape=(28*28,))) #은닉층1# 규제화를 하고자 하는 경우 from tensorflow.keras import regularizers 사용# model.add(layers.Dense(512, activation = 'relu', kernel_regularizer=regularizers.l2(0.001), input_shape=(28*28,)))model.add(layers.Dense(10, activation = 'softmax')) # 출력층: 출력노드는 10model.summary()# 인풋 785(피쳐 수 + 편향 노드 수) * 덴스레이어 노드 수 512 = 401920# 덴스레이어 513 * 출력층 10개 = 5130cs 이렇게 쌓여진 모델은 다음과 같습니다.
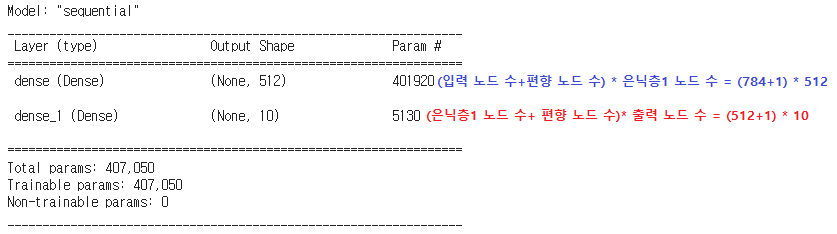
(4) 이미지 데이터 reshape(가래떡 뽑기) & normalizing
123456789101112131415161718192021# 3D array에서 2D array로 변환(reshape)train_images.shape # (60000, 28, 28)train_images = train_images.reshape((60000, 784)) # reshape로 형태를 변환test_images = test_images.reshape((10000, 784))# reshape 결과 확인train_images.shape # (60000, 784)train_images[59999] # (784,)"""0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 89, 219,254, 97, 67, 14, 0, 0, 92, 231, 122, 23, 203, 236, 59,...."""# 이미지 normalizingtrain_images = train_images.astype('float32')/255 # 각 셀이 저장한 숫자 255로 나누면 0~1사이로 normalized됨test_images = test_images.astype('float32')/255train_images[59999]"""0. , 0. , 0.43137255, 0.99607843, 0.85490197,0.99607843, 0.45490196, 0. , 0. , 0."""cs 그냥 fit으로 훈련을 시키면 됐었던 회귀문제에 비해 이미지는 과정이 조금 더 복잡합니다 ㅠㅠ 이는 이미지 데이터셋이 (60000, 28, 28)상태의 3D array이기 때문인데요. 즉, input으로 바로 와르르르 들어가기에는 너무 똥똥하기에(?) reshape로 얄쌍하게 만들어주어야 합니다 ㅋㅋ.
reshape를 적용할 경우 데이터셋들은 3D array(60000, 28, 28)에서 2D array(60000, 784)로 변환이 되는 한편, 개별 이미지들은 이 작업으로 인해 인풋으로 들어갈 수 있을 만큼의 사이즈인 1차원의 array로 변하게 됩니다.
가령 train_images[59999]의 경우 1차원의 784개의 원소를 가진 1D array가 되었습니다 :D
다만 아직 한가지가 더 남았습니다. feature값, 즉 개별 픽셀값을 0과 1사이로 normalizing해주어야 합니다.
이에 따라 매 픽셀을 255로 나누는 train_images.astype('float32')/255 등을 수행하여 normalizing해줍니다. 이제야 신경망에 들어갈 준비가 끝난........ 줄 알았지만!!!
(5) 라벨 원 핫 벡터화
이미지에 대해 처리를 해 주었으니 라벨에 대해서도 처리를 해주어야 합니다.
123456789101112131415# 라벨의 원핫벡터 변환# one-hot vector => 원소의 수 = 종속변수가 취할 수 있는 값의 수 인 벡터# 종속변수가 취하는 값(0~9)의 위치에 해당하는 원소 = 1, 나머지 원소 = 0인 벡터from tensorflow.keras.utils import to_categoricaltrain_labels_one_hot = to_categorical(train_labels) # ex. [0 0 0 0 0 0 0 1 0 ] #레이블이 8인 경우test_labels_one_hot = to_categorical(test_labels)# 원핫 벡터 이전test_labels.shape # (10000,)test_labels[0] # 7# 원핫 벡터 이후test_labels_one_hot.shape # (10000, 10)test_labels_one_hot[0] # one-hot vector (7번째 값만이 1)# array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.]cs 원핫 벡터란 하나만 뜨거운 벡터, 즉 하나만 1이고 나머지는 0인 벡터입니다. 여기서는 정답 레이블만 1이고 나머지 레이블은 0이 되는 형태가 되어야 합니다.
지금은 숫자(정확히는 numpy.unit8)인 그냥 60000개, 10000개의 라벨에 to_categorical 함수를 적용하여 원핫 레이블로 만들어줍니다. train_labels_one_hot = to_categorical(train_labels) 등이 여기에 해당합니다.
실제로 확인해보면 원핫 벡터 이전 10000개의 그냥 숫자들이 10000개의 원핫 벡터(array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0...]....)로 바뀐 것을 볼 수 있습니다.
(6) compile
(주요 하이퍼파라미터: 옵티마이저, 비용 함수, 평가 metric)
1234567from tensorflow.keras import optimizersrmsprop = optimizers.RMSprop(learning_rate=0.001)model.compile(optimizer=rmsprop,loss='categorical_crossentropy', # 종속변수의 값 = 2 인 경우, binary_crossentropy, 종속변수 값이 2개 초과한 경우는 categoricalmetrics=['accuracy'])# metrics => 모형의 성능을 무엇으로 평가할 것인지에 대한 것# 'accuracy' => 전체의 관측치 중에서 몇 개 관측치의 종속변수 값을 제대로 맞혔는지를 의미cs 이제야 model 컴파일을 합니다. 컴파일 시에는 옵티마이저, 비용함수, 성능 평가 방법을 선택합니다.
비용함수의 경우 라벨이 2개를 초과한 다진 분류이므로 Cross Entropy 중 categorical cross entropy를 사용합니다. 만일 라벨이 2개 뿐인 이진 분류라면 binary_crossentropy를 사용합니다.
metric의 경우 모형의 성능을 어떤 지표로 평가할 것인지를 정하는 하이퍼파라미터인데, 보통 정확도(accuracy)를 사용합니다.
(7) 모델 훈련(fit)
(주요 하이퍼파라미터: 에폭수, mini-batch 수, 검증 데이터 비율)
123# 검증데이터 사용 시history = model.fit(train_images, train_labels_one_hot, epochs=10, batch_size=128, validation_split=0.2)# 60000/128 이므로 한 에폭에서 469번의 업데이트가 일어남cs 아까 회귀에서는 validation set을 사용하지 않았지만 여기서는 사용했습니다. 훈련 데이터의 20%를 떼서 훈련 자체에 사용하는 대신, 훈련 중간중간 잘 되고 있는지 '검증'하는데 활용하는 데이터로 사용한 것입니다. 검증 데이터가 적용될 경우 출력도 약간 바뀝니다 :D
지금같은 경우는 batch를 128로 했으므로 훈련 데이터 48000개에 대해 한 에폭 당 총 375번의 가중치 업데이트가 일어납니다.

회귀문제와 다르게 accuracy, val_loss, val_accuracy가 보입니다. accuracy는 metric을 accuracy로 지정했기 때문에 출력되는 것이고, val_의 경우 validation셋을 사용했기 때문입니다. 아까보다 뭔가 더 딥러닝스럽게 보입니다 ㅋㅋㅋ
(8) 평가 및 예측
위에서도 그러하였듯이 .predict()를 사용하여 한 이미지에 대해서 예측을 할수도, 전체 test 셋에 대해 evaluate를 사용해 평가를 할 수도 있습니다.
1234567891011121314151617181920212223242526# 평가 데이터에 대해 테스트: .evaluate 함수model.evaluate(test_images, test_labels_one_hot)# 비용함수 값, accuracy 값 출력"""313/313 [==============================] - 1s 2ms/step - loss: 0.0794 - accuracy: 0.9784[0.07941931486129761, 0.9783999919891357]"""# 하나의 이미지에 대해 예측하기import numpy as npnp.set_printoptions(suppress=True, precision=10)model.predict(test_images[0:1]) # predict 함수의 인자는 리스트 형태"""array([[0. , 0. , 0.0000000155, 0.0000002198,0. , 0.0000000001, 0. , 0.99999976 ,0.0000000001, 0.0000000143]], dtype=float32)"""#10개 원소를 가진 array: 확률값을 나타내는 중, 7에 대해 가장 높은 확률(0.99999976)을 가짐test_labels[0] # 실제 정답 7labels = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]labels[np.argmax(model.predict(test_images[0:1]))] # 7이라고 예측# 7인지 plot으로 확인plt.imshow(test_images[0].reshape(28, 28), cmap='gray')plt.show()cs 우선 평가 데이터 전체에 대해 예측을 할 수도 있습니다. evaluate 함수를 사용합니다. 사용 하면 loss값과 accuracy 값을 매우 정밀하게 ^^;;; 출력합니다.
위에서 그러하였던 것처럼 .predict()를 사용하여 한 이미지에 대해서 예측을 할 수도 있습니다. 테스트셋 첫 번째 이미지에 대해 .predict를 할 경우, 각 라벨에 대한 확률값이 array형태로 리턴됩니다. 가장 높은 확률을 가진 라벨은 7번째 원소이므로 이 이미지의 라벨은 7로 예측된 것을 알 수 있습니다. 또한 실제로 정답도 7입니다!
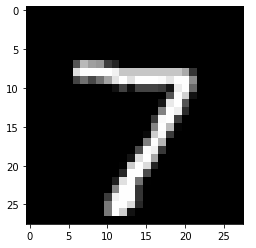
(9) loss 및 accuracy 확인하기
1234567891011121314151617import matplotlib.pyplot as plt# loss값 확인하기plt.plot(history.history['loss']) # history에 저장된 loss랑plt.plot(history.history['val_loss']) # val_loss에 대해 plotplt.xlabel('epoch') # x축은 epochplt.ylabel('loss') # y축은 lossplt.legend(['train', 'val']) # 선은 train, val로 표시해주세요~plt.show()# accuracy 값 확인하기plt.plot(history.history['accuracy']) # history에 저장된 accuracy에 대해 plotplt.xlabel('epoch') # x축은 epochplt.ylabel('accuracy') # y축은 accuacyplt.legend(['train']) # 선에 train으로 표시해줘!plt.show()cs 역시 마찬가지로 loss와 accuracy에 대해서 선을 그릴 수 있습니다.
아까 validation도 사용했으므로 val_loss에 대해서도 그릴 수 있습니다 :D

3. FFNN의 한계
이렇게 보면 FFNN만으로도 이미지 분류까지 완벽한 것으로 보이는데요...
Fashion MNIST라는 것이 있습니다. 실제로 얘를 동일한 방법으로 실험하게 될 경우 성능이 약 80%밖에 나오지 않게 됩니다. 흑백 데이터에 이러할진대 컬러 이미지의 경우 제대로 분류가 되지 않을 것은 불보듯 뻔합니다. 이에 따라 이미지 처리에 특화된 CNN 알고리즘이 나오게 됩니다.
'general ML, DL, NLP > 딥러닝' 카테고리의 다른 글
7. CNN(Convolutional Neural Network) (0) 2022.04.20 6. Overfitting 과적합 (0) 2022.04.20 3. 경사하강법 & 4. optimizer (0) 2022.04.19 2. 활성화 함수 (0) 2022.04.19 1. 딥러닝 기초 (0) 2022.04.19