-
3. 경사하강법 & 4. optimizergeneral ML, DL, NLP/딥러닝 2022. 4. 19. 18:06
*본 게시물은 22-1학기 연세대학교 일반대학원 딥러닝을이용한비정형데이터분석(이상엽 교수님) 수업 내용을 정리한 것입니다.
3. 경사하강법 - 비용함수 최소화 방법
1. 신경망에서의 학습
신경망에서 '학습'이란 모형의 총 오차를 나타내는 비용함수를 최소화하는 파라미터 값을 찾는 것입니다. 이에 따라 optimization problem이라고 볼 수도 있습니다.
비용함수를 최소화 하는 주요 방법에는 다음과 같은 방법들이 있습니다.
- Normal Equation: 비용함수가 2차함수와 같이 볼록한 convex 함수일 때만 사용 가능합니다.
그러나 대부분 딥러닝의 비용함수는 convex 형태가 아니고, 파라미터도 많기에 딥러닝에서는 사용되지 않습니다.
- Gradient Descent 경사하강법
가중치의 값을 여러번 업데이트하면서 비용함수 값을 점점 최소화해나갑니다. 신경망에서는 회귀에 쓰이는 MSE 비용함수나 분류에 쓰이는 Cross Entropy 모두 경사하강법을 사용하게 됩니다. 경사하강법은 대략 이렇게 생겼습니다.
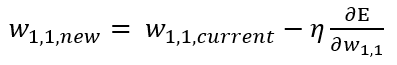
뒤에 다루겠지만 경사하강법은 단점이 있습니다(saddle point와 느린속도가 그것입니다). SGD, BGD, mini-batch GD 등은 Gradient Descent의 단점을 보완한 방법들입니다.
2. 경사하강법의 종류
경사하강법(Gradient D은 한번 업데이트 시 사용되는 데이터 포인트(관측치) 양에 따라 3가지로 구분됩니다.
1) Stochastic Gradient Descent : 데이터 중 1개 사용
한 번 업데이트 할 때, 랜덤(stochastic)하게 선택된 하나의 데이터 포인트(관측치)만을 사용합니다.
즉 N개 관측치가 존재할 때, 업데이트 시 1개를 사용합니다.
업데이트 방향이 일정하지 않고 수렴에 시간이 오래 걸리는 것이 단점입니다.
가령 비용함수가 MSE일 때, SGD를 사용하면 다음과 같이 나타낼 수 있습니다.

2) Batch Gradient Descent: 데이터 전체 사용
한 번 업데이트를 할 때 마다 비용함수 계산을 위해 전체 데이터를 모두 사용하는 방법입니다.
즉 N개 관측치가 있으면 한 번 업데이트 시 N개를 모두 사용하는 방법입니다.
메모리가 많이 필요하며, 계산에 시간이 오래걸립니다.
비용함수가 MSE일 때, Batch GD를 사용하면 다음과 같습니다. N부분이 전체 관측치임을 확인할 수 있습니다.

3) Mini-batch Gradient Descent: 일부 데이터만 사용
한 번 업데이트 시 데이터 중 일부(mini-batch)를 사용합니다. 다음 업데이트에는 또 다른 일부를 사용하면서 가중치를 업데이트합니다.
즉, N개의 관측치가 있을 경우 일부인 h개를 사용하는 방법이며, 실제로 제일 많이 쓰이는 방법입니다.(batch=32, 64 등으로 많이 보셨을겁니다 :D)
비용함수가 ME일 때 Mini-batch를 계산하는 식은 다음과 같습니다. 식이 어렵지만 결론적으로 h개의 관측치를 사용한다는 것이 핵심입니다.

4. Optimizer
1) 경사하강법의 문제점
사실 그동안 계속 다뤄온 경사하강법은 완벽하지 않습니다 ^^;; 허허.. 경사하강법에는 기본적으로 2가지 문제가 존재합니다.
(1) 비용함수의 saddle point(안장점) 문제
경사하강법은 안장점을 잘 벗어나지 못합니다. 즉 떨어질 만큼 떨어진 줄 알았는데 아직도 지하가 있더라... 같은 느낌입니다(...)

맨 아래로 또로로 굴러떨어져서 비용함수를 최소화하는 최적의 가중치를 찾아야하는데 안장점에 갖혀서 나오지 못하고 있는 모습입니다. 안장점을 벗어나지 못한 이유는 saddle point가 local minimum이라 미분값이 0이 되어 더이상 가중치 업데이트가 일어나지 않기 때문입니다. 즉 안장점은 비용함수 값을 최소화(minimize)하는 파라미터 값이 아닌 지점입니다.
(2) 느린 속도
경사하강법은 ① 업데이트된 정보가 현재 시점에서는 사용되지 않는 것, 그리고 ② 학습률이 변경되지 않는다는 단점이 존재합니다. 이 두 가지는 (1) saddle point와 (2) 느린속도 모두를 야기합니다. 또한 경사가 급한 곳이든 완만한 곳이든 업데이트 속도가 동일해, learning rate decay가 없는 업데이트 방법이라 할 수 있습니다.
2) 다양한 optimizer들의 등장
위의 과거 업데이트 사용 제한, 학습률 불변 등의 문제를 해결하기 위해 기본 경사하강법 업데이트 공식을 약간씩 수정/보완한 optimizer들이 개발되었습니다. 예로는 Momentum, Adagrad(Adaptive Gradient), RMSprop(Root Mean Square Propagation), Adam(Momentum+RMSProp) 등이 있습니다.

keras를 이용했을 때 주로 optimzer=로 지정하게 되는 하이퍼파라미터들이라 익숙하실 것입니다..*^^* (1) Momentum
모멘텀은 이전 업데이트 정보가 현재 시점에 쓰이지 않는 단점으로 보완하고자 개발되었습니다. 이에 따라 이전 업데이트 정보를 기억하여 현재 업데이트에 반영하는 방법을 채택하였습니다. 지금은 그렇게 많이 쓰이는 옵티마이저는 아니라고 합니다 :(

기존 경사하강법 식에 이전 update 내용이 추가된 것을 볼 수 있습니다. 모멘텀은 경사하강법에 비해 ① local minimum/saddle point를 잘 회피하고, ② 수렴속도가 빠르다는 장점이 있습니다.
(2) Adagrad(Adaptive Gradient)
Adagrad는 학습률이 계속 고정되어 변하지 않는 단점을 보완하고자 개발되었습니다. 즉 업데이트 횟수에 관계없이 학습률을 다르게 줄 수 있습니다.
학습률을 다르게 줄 때 지금까지 업데이트 된 정도를 반영하여, 업데이트가 많이 된 파라미터는 학습률을 작게 주는 learning rate decay가 적용됩니다.

빨간색은 '에타'라는 것으로, 학습률을 표현합니다. 에타를 줄이기 위해 초록색으로 나눠준 것을 확인할 수 있습니다. 초록색 안에는 주황색으로 표현된 gradient의 총합이 있는데요, 총합이 계속 커지면 분모가 커지기에 점점 0에 가까워지게 됩니다. 그렇게 된다면 어느 순간 업데이트가 중지되기에 Adagrad는 실제로 많이 쓰이지는 않습니다.
파란색은 입실론으로, 분모가 0이 되는 것을 방지하는 역할을 합니다. 보라색은 t 번째에서의 gradient 값을 뜻합니다.
(3) RMSProp(Root Mean Square Propagation)
Adagrad의 확장버전입니다. 무조건적으로 줄어드는(위 그림의 주황색으로 인한 ^^;) 학습률 문제를 보완한 것으로, 총합이 아닌 과거 gradient들의 평균을 사용하게 됩니다.

(4) Adam
Adam은 momentum과 RMSProp을 합친 옵티마이저입니다. 이에 따라 이전에 업데이트된 정보를 사용하는 한편 학습률이 변할 수 있습니다.

3) 옵티마이저 간 비교
보통 옵티마이저 간 비교를 하면 안장점을 데굴데굴 굴러가는 여러가지 옵티마이저들의 gif가 생각날 것입니다. ㅋㅋㅋ
밑 두 그림의 원출처는 여기입니다. optimizer에 대해 더 자세히 보고 싶은 분들은 방문하셔도 좋을 것 같습니다.
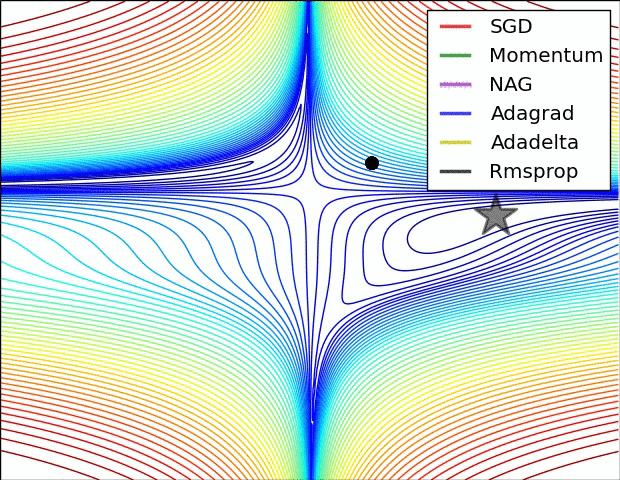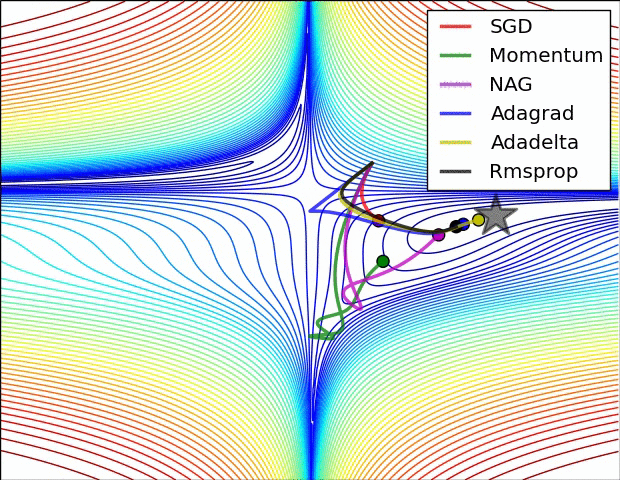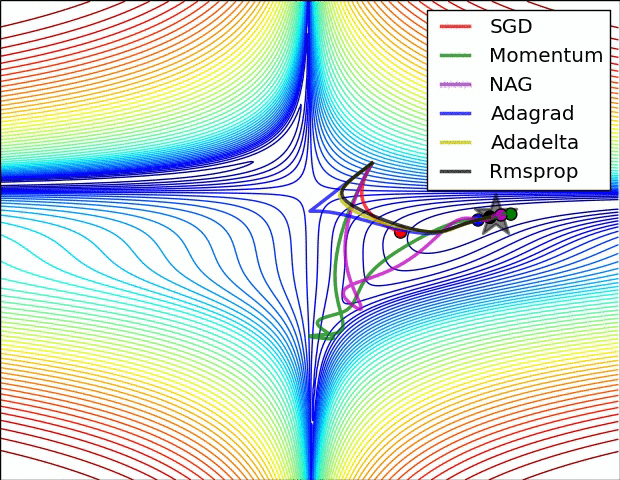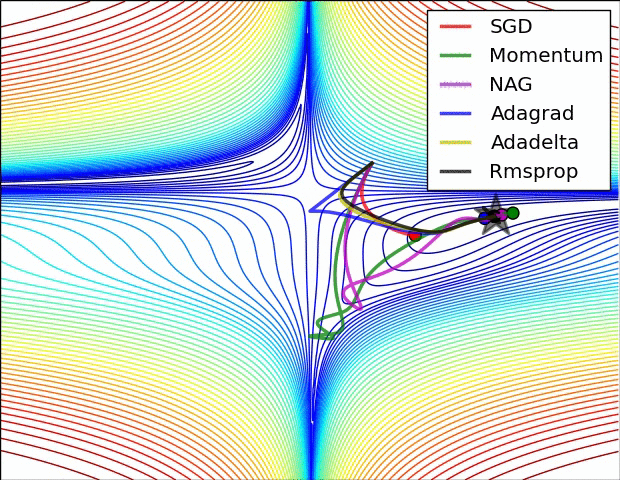
optimization on loss surface contours 
optimization on saddle point 'general ML, DL, NLP > 딥러닝' 카테고리의 다른 글
7. CNN(Convolutional Neural Network) (0) 2022.04.20 6. Overfitting 과적합 (0) 2022.04.20 5. FFNN(Feed Forward Neutral Network) (0) 2022.04.20 2. 활성화 함수 (0) 2022.04.19 1. 딥러닝 기초 (0) 2022.04.19