-
A survey on evaluation of large language modelsGenerative AI/benchmarks 2024. 7. 30. 09:45
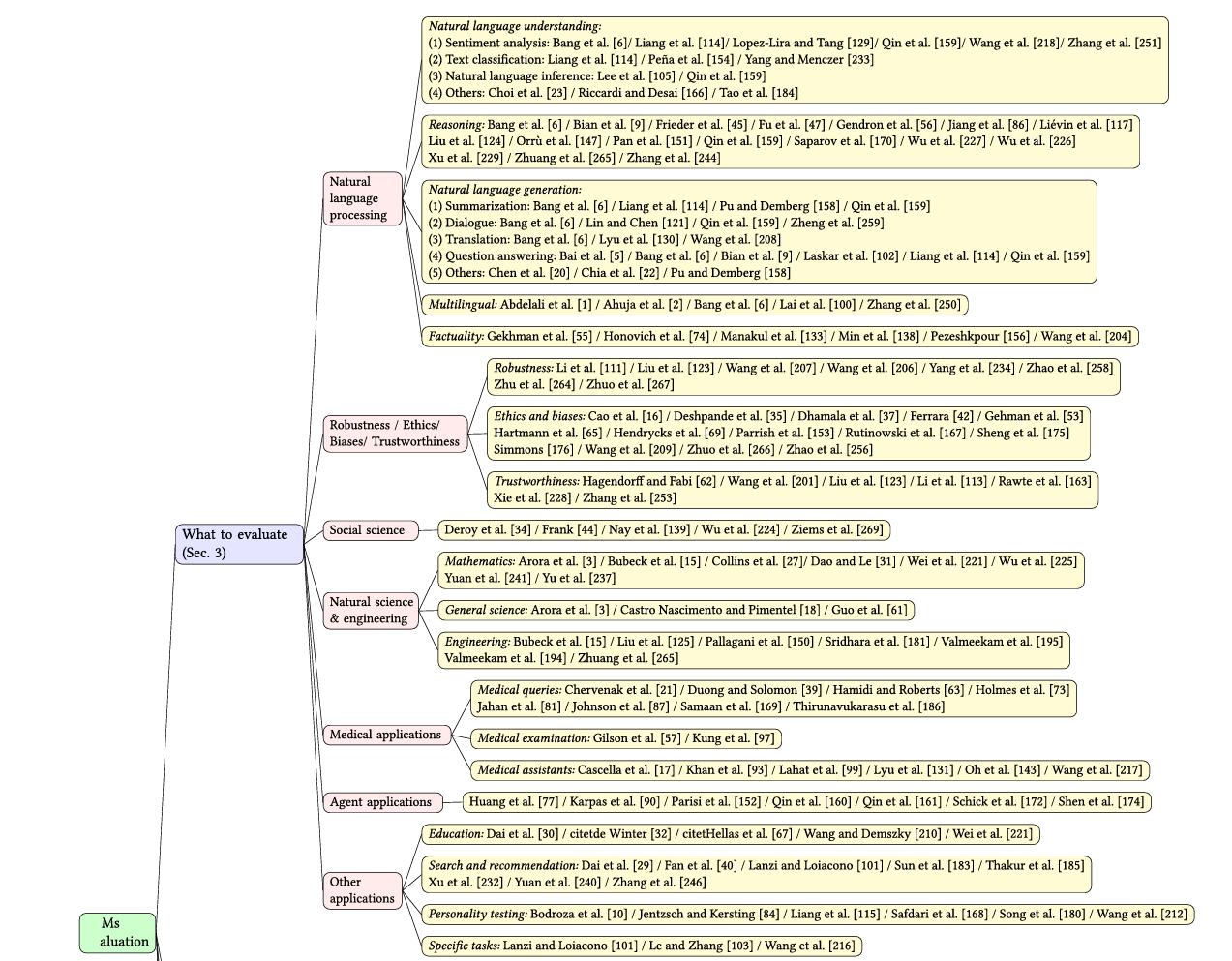
Chang, Y., Wang, X., Wang, J., Wu, Y., Yang, L., Zhu, K., ... & Xie, X. (2024). A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3), 1-45.


'Generative AI > benchmarks' 카테고리의 다른 글