-
Can Large Language Models Understand Real-World Complex Instructions?Generative AI/benchmarks 2023. 11. 30. 02:54
* He, Q., Zeng, J., Huang, W., Chen, L., Xiao, J., He, Q., ... & Xiao, Y. (2023). Can Large Language Models Understand Real-World Complex Instructions?. arXiv preprint arXiv:2309.09150. (AAAI accepted)
* 주안점
- 대부분은 English model들이 인스트럭션 이해를 잘함
- 한편 Chinese data가 Chinese model 성능을 높임
- 모델 34개 정도는 실험해야 accept이 되는구나...
<요약>
ㅇ LLM들의 발전은 눈부시나 complex instruction을 이해하는데 한계
- what is complex instruction?
1) complex task description (multiple tasks, constraints)
2) complex input (long context, noise, heterogeneous information, multi-turn format)
- 이에 따라 LLM들은 task descriptions에 대해 semantic constraints / incorrect formats 생성 / length violation / sample count constraints / input text에 대한 unfaithful한 텍스트 생성 등의 문제를 보임
ㅇ 기존 벤치마크: close-ended, simple하기에 LLM이 compelx instruction 에 대해 이해하는지 측정하는데 한계
ㅇ CELLO: evaluating LLM's ability to understand complex instructions.
- 이에 따라 complex instruction의 8가지 특징 선정
- real-world scenario에 기반한 evaluation datasets
- 4개의 평가 기준(criteria) & 측정 기준 고안
- Chinese-oriented, English-oriented 모델간 complex instruction 이해 성능 비교

1. Introductions
1) complex instruction의 종류
(1) complex task descriptions: task 설명 시 다양한 제한 사항들이 따름
- understand multiple tasks (multi-tasking)
- semantic / format / quantity constraints
- use of predefined callable functions
- structured formation: 인간의 reasoning processes 모사
(2) complex input: input text 관련
- long context, noise, error accumulation
- heterogeneous information
- multi-turn 형태의 인풋 텍스트
2) complex instruction benchmark: CELLO
ComplEx instruction understanding ability of Large Language mOdels
- complex instruction의 8개 특징 / 4개의 평가 기준 / 자동 평가 지표로 측정
* 새로운 벤치마크가 필요한 이유
- 기존 벤치마크들은 대부분 close-ended
> real-world 기반 complex instruction 들은 대부분 open-ended 성격
- 기존 연구들은 대부분 GPT4 Evaluation을 수행하나, bias 문제가 있음
- comlex instruction를 가진 벤치마크들의 binary pass rate 평가 방법은 strict하고 coarse-grained함
> 때문에 대체로 작은 LLM들에 대해 매우 낮은 점수를 부여
2. Related Work : 논문 참조
3. CELLO Benchmark
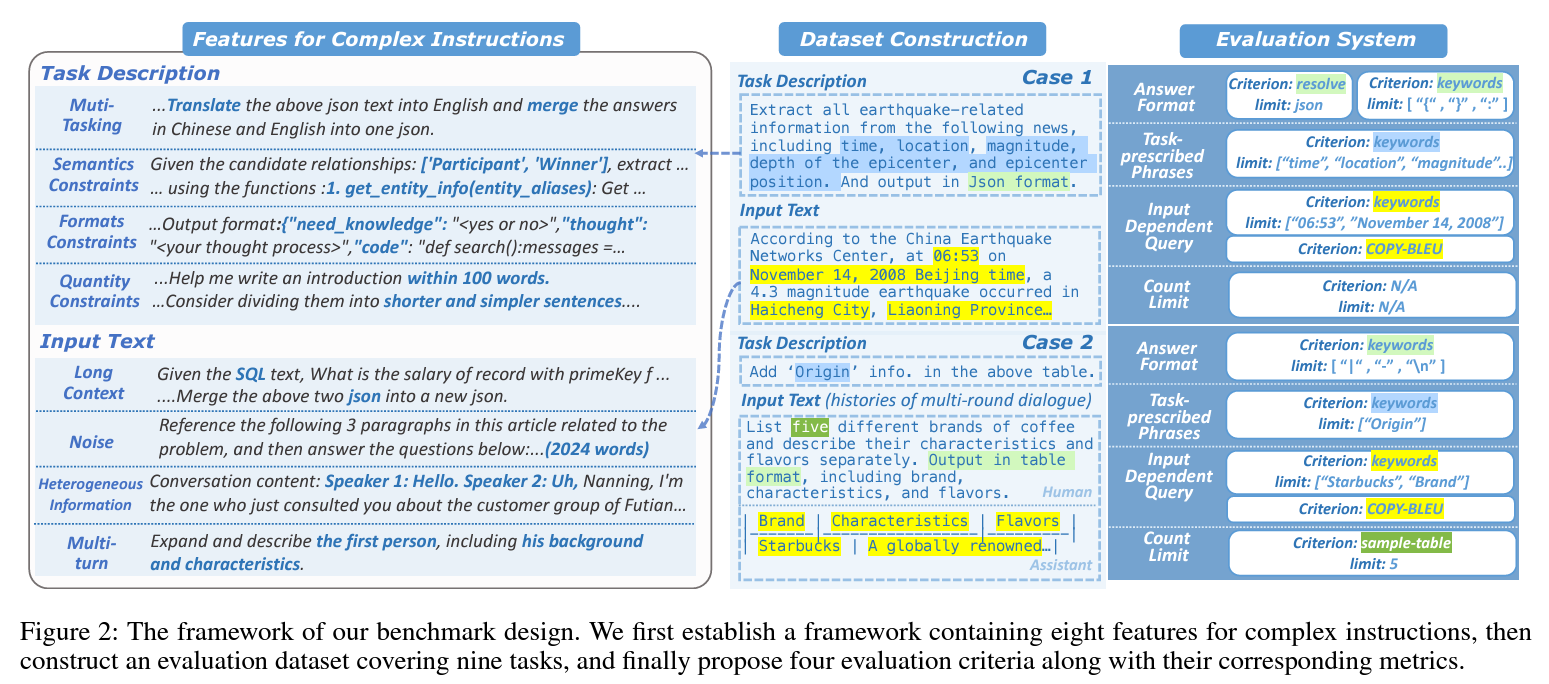
1) Dataset Construction
- real scenario에 기반하여 데이터 수집, 9개 task
- In-breadth Evolution, In-depth Evolution 기준에 따라 complex instruction 수집
(1) Data Source and Selected Tasks
To ensure the real scenarios and prevent the data leakage, data are come from:
i) Real World project requirements
- ChatPDF 등 회사와 협업한 프로젝트, industry information extraction, audio summarization...
ii) The usage logs: 연구팀에서 개발한 LLM에 남은 usage log (6개월) 활용
(2) 9 tasks에 대한 6 categories
1) Complex NLP Tasks
- 실제 시나리오 기반 데이터들은 noise가 많고 long context를 가짐
i) Long Text Summarization
ii) Long Text Closed-domain Question Answering
iii) Long Text Keywords Extraction
iv) Complex Information Extraction
- 주어진 글에서 특정 대상(object)에 대한 특정 정보를 찾은 뒤, 미리 정해진 format으로 리턴
2) Meta-prompt; 프롬프트를 만드는 프롬프트
varied instructions, rich input topics, few-shot smaples, clear format requerements 등을 포함
최근에 개발된 task에서 meta-prompt 수집
- dimenison perception, instrcution polishment, complex extraction, Stable Diffusion prompt generation, taxonomy construction..
3) Planning
- 사람의 사고 과정을 반영, 연구에서는 single-step planning 사용
- CN-DBpedia, fund knowledge base, Langchain 등에 기반한 planning task 프롬프트 수집
4) Well-guided writing
기존 글쓰기 관련 벤치마크에서는 complex feature를 고려하지 못하였으며, single-turn interaction만 가능
- 이를 보완하여 태스크 고안: various single-turn complex instructions with various features / multi-turn instructions
5) Detailed brainstorming
브레인스토밍을 통해 챗봇의 직관력을 기를 수 있음
- 그러나 기존 데이터셋은 매우 단순
- 이에 따라 single-turn brainstorming data (detailedd requirements) / multi-tun brainstorming (realistic user inter.) 개발
6) Data Evolution
수집된 complex instruction들을 사용하여 robust, reliable한 evaluation을 하기 위함
i) In-breadth Evolution: 수집한 complex instruction에 대한 diversify
① task description relocation: 중요 정보 배치 위치
② task description Paraphrasing
③ task Emulation: 한 태스크에 대상을 다양화하여 조직(ex.plannig: 비행기 예약, 여행 일정...)
ii) In-depth Evolution: 하나의 instruction에 대한 고도화
① Constraints Addition: output format, semantics, quantity...
② Multi-round Interaction: real-scenario에 따라 multi-turn
2) Criteria: Metrics 고안 부분으로 논문 참조
4. Experiments
1) Evaluated Models
- 34개 모델 동원: 다른 벤치마크에서 뛰어ㅓ난 성능을 이미 보인 것
- model size, context lengt, instruction tuning data size 등에 따라 구분
- 3 categories: Chinese-oridented models (FS; From Scratch), Chines-oriented models (CP; Continue Pretraining), English-oriented Models
2) Task-categorized Performances
(1) general comparisons
- Open-Chat-V3.2가 가장 잘 수행, 그다음 Vicuna-V1.4-13B, ChatGLM(6B)
> small LLM 도 complex instruction을 잘 이해하고 수행
- Chinese-oriented(FS)가 English-oriented model 이랑 비슷한 성능
> complex instruction이 반드시 language-dependant하지는 않음
- base model, vocaburary, supported context length는 성능과 강한 상관관계
(2) Complex Task Description
- 상위 5위 모델 중 4개가 English-oriented
> ability of complex task description에는 영어 모델이 강세
- 사이즈가 중요한 것은 역시 아님
- best-perfoming group의 입력 context length: 4096
>complex task description에서는 length가 주요 요소가 아님
(3) Complex input text
- 10위 중 7위 모델은 Chinese-oriented models
> Chinese-oriented 모델이 길고 노이즈가 많은 중국어 텍스트에 강건
- 모델 크기에 따라 성능도 비례, 단! context length는 성능과 반비례
3) Criteria-categorized Performance
(1) answer format : 영어 모델들이 압도적으로 잘 함
- 퓨샷, 코드 생성에 매우 능한 것이 transfer된 것으로 보임
(2) Task prescribed phrases: 상위 3모델이 중국어 모델
- 중국어 데이터가 chinese semantic restriction 이해를 도운 것으로 보임
4) Comparisons between Benchmarks
- Chinese knowledge (C-eval, CMMLU, GAOKAO)
> 작은 모델들이 성취가 좋으며, GPT3.5와 similar
- Complex reasoning (BBH, GSM8k) & Programming (HumanEval) : 작은 모델들의 성취가 어려움
5. Conclusion
- complex instruction에 대한 Chinese dataset & benchmark 제안에 의의
RQ
위 논문을 통해 instruction과 input의 수행 조건, 길이, 구조 등이 복잡해질수록 기계의 성능이 저하되는 것을 확인
이에 따라 아래와 같은 가설을 세울 수 있음
RQ1) 수행 조건이 간략한 simple instruction일 때, 기계는 정보(knowledge)가 많은 질문일수록 성능이 인간만큼 높아질 것이다.
RQ2) Complex instruction(ex. reasoning 포함 등)일 때, 기계의 수행 성능이 낮아질 것이다.
RQ3) Complex instruction을 정보가 많은 simple instruction으로 치환할 경우 기계 수행 성능이 다시 높아질 것이다.
RQ4)
'Generative AI > benchmarks' 카테고리의 다른 글