TextRank: Bringing Order into Texts
*본 포스팅은 22-1학기 연세대학교 일반대학원 텍스트마이닝(송민 교수님) 수업을 정리한 것입니다.
2004년 'TextRank'란 논문이 발표되었습니다. 이 글은 논문 내용을 간추린 것입니다.
1. Introduction
(1) 그래프 기반 랭킹 알고리즘
그래프 기반 랭킹 알고리즘은 vertex(=노드)의 중요도를 그래프에 표시해 놓았으며, vertex의 중요도는 전체 그래프의 global information을 사용하여 반복적(recursive)으로 도출됩니다. 이는 vertex의 중요도가 1) 중요한 vertex에 의해 가리켜지거나 2) 가리킴을 많이 받을수록 중요도가 커지기 때문입니다. 이 그래프 기반 랭킹 알고리즘을 사용하면 citation analysis, social networks, Web의 link-structure 등을 표시할 수 있습니다. 또한 NLP에 적용될 경우 key phrase 자동 추출, 추출 요약(extractive summarization)에도 활용할 수 있습니다.
(2) TextRank
TextRank는 그래프 기반 모델입니다. 이에 따라 텍스트에서 추출된 그래프를 활용하여 핵심어(keyword)나 문장(sentence)을 추출(extraction)하는 task를 수행합니다.
2. TextRank 모델
앞서 설명했던 것처럼 TextRank는 그래프 기반 랭킹 알고리즘입니다. 본래 그래프 기반 랭킹 알고리즘으로 유명한 것은 Google의 PageRank 이며, 눈치 채셨겠지만 TextRank는 PageRank를 텍스트에 적용한 모델입니다(뒤에서 다룹니다)

그래프 기반 랭킹 알고리즘들은 그래프 내 vertex들의 중요도를 결정하는 것이 필요합니다. 중요도 결정에는 global information이 고려되며, 전체 그래프에서 반복적(recursive)으로 도출됩니다. 이에 기반이 되는 아이디어는 Voting과 Recommendation입니다. TextRank에서 voting이란 각 vertex들이 화살표로(혹은 edge로) 다른 vertex를 가리키는 행위라 할 수 있습니다. Recommentation이란 중요도가 큰 vertex가 다른 vertex를 지목하는 것입니다.
Recursive하게 vertex의 score가 결정이 된다는 것은 vertex의 중요도가 다음 2가지로 결정된다는 의미입니다. 일단 voting을 많이 받으면 중요도가 커지는 것이고, 중요도가 커지면 다른 vertex를 recommendation할 수 있는 힘이 생깁니다 ㅎㅎ
| <vertex score 결정> 1) 얼마나 많은 vertex와 연결이 되어있는가: voting이 얼마나 많은가 2) 어떤 vertex와 연결이 되어 있는가: recommendation을 받았는가 |
vertext score 결정을 수식으로 나타내면 다음과 같습니다.

그래프 내의 vertex들은 임의의 값(arbitrary values)으로 초기화됩니다. 이후 주어진 기준 값(threshold)보다 밑에서 수렴(convergence)을 달성할 때 까지 학습을 반복합니다. vertex의 score는 초기 수치에 영향을 받지 않고(즉 초기화된 값에 따라 결정 되는 것이 아닌) convergence를 달성하기 위한 interation 횟수에 따라 결정됩니다.
(1) Undirected Graphs
기존 PageRank처럼 전통적인 그래프 기반 알고리즘은 보편적으로 '방향성(directed)'이 있는 그래프에 대해 반복적으로 적용되어 왔습니다. 그러나 TextRank는 방향성이 없어도(undirected) 반복적인 그래프 기반 랭킹 알고리즘 적용이 가능합니다. 이러한 무방향성 그래프에서는 Vertex의 in-degree(In)와 out-degree(Out)의 값이 같아집니다.
방향성과 무방향성 모두 그래프의 연결성이 높아짐에 따라 edge가 많아지면 convergence를 위한 iteration 횟수가 줄어들게 됩니다. 즉 소수의 iteration만으로 수렴이 가능해지며, 방향성과 무방향성 모두 비슷한 convergence curve를 보이게 됩니다.
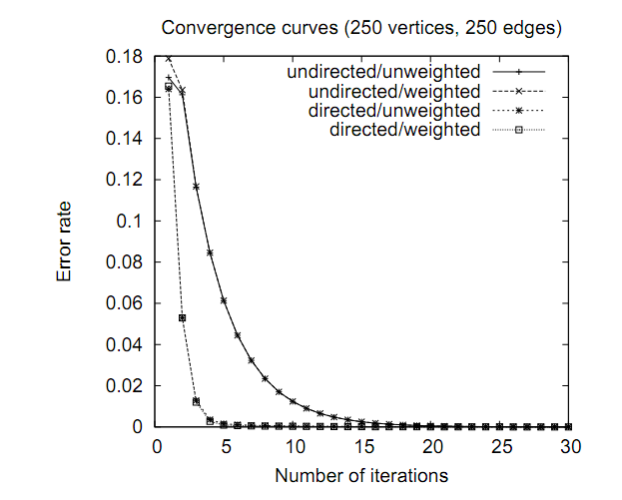
(2) Weighted Graphs
기존 PageRank는 unweighted graph를 가정했었습니다. 이는 웹페이지가 다른 페이지로 이동하는 링크를 표시할 때 링크에 복수개(multiple)의 page를 달아놓거나 혹은 동강난(partial) page를 달아놓지 않기 때문입니다^^; 그러나 TextRank에서는 자연어 텍스트로부터 그래프가 생성되기에 vertex 간 복수개 혹은 부분적인 링크를 다는 것이 가능합니다. 이와 같이 weighted graph에서는 edge의 가중치를 통해 vertex간 연결 강도를 그래프에 포함시킬 수 있습니다.
이를 수식으로 표현하면 다음과 같습니다. 주황색 시점에서 비교하였을 때, 초록색 화살표로 표시된 undirected/weighted 가 훨씬 더 빠른 수렴을 보입니다.

(3) Text as a Graph
텍스트를 바탕으로 그래프 기반 랭킹 알고리즘을 적용할 경우 '텍스트를 표현하는 그래프'가 생성됩니다. 또한 이 그래프는 '단어 및 다른 entity를 유의미한 관계로 상호 연결할 수 있는 그래프'가 됩니다. 이때 텍스트로 된 vertex는 비단 단어 뿐만 아니라 문장, 연어(collocation) 등 매우 다양한 단위들로 구성할 수 있습니다. 또한 vertex간 관계 역시도 lexical semantic relation, contextual overlap 등 다양하게 나뉩니다.
그래프 기반 랭킹 알고리즘을 자연어 텍스트에 적용할 때에는 다음 4단계를 거칩니다.
| 1. Identity text units | task를 분명하게 정의하여 단위(unit)를 결정합니다. 이 단위를 vertex로 하여 그래프에 포함시킵니다. |
| 2. Identify relations | 각 vertex(=text unit)들을 연결시켜야 합니다. 연결 시 두 vertex간 관계를 활용하여 edge로 잇습니다. |
| 3. Iterate the graph-based ranking algorithm | 수렴 상태에 도달할 때까지 그래프 기반 알고리즘을 학습시킵니다. |
| 4. Sort vertices based on their final score | vertex들을 최종 점수에 따라 나열합니다. |
3. 핵심어 추출(Keyword Extraction)
핵심어 추출은 문헌을 가장 잘 나타낼 수 있는 핵심어들의 집합을 자동으로 구별하는 task입니다. 이를 통해 자동 인덱스 형성, 텍스트 분류, 짧은 요약, 용어 추출(terminology extraction), 도메인 특화 사전(domain-specific dictionary) 등을 수행할 수 있습니다. 핵심어를 추출하기 위한 방법은 빈도 기준/TextRank 방법이 있습니다.
빈도 기준 접근법은 문서 내 많이 나타난 단어가 대표성을 띈다는 것을 전제로 하는 접근법입니다. 그러나 늘 그렇듯이 성능이 좋지는 않습니다(....) 빈도 기준 접근법 중 2004년 당시 SOTA를 달성한 방법은 지도학습 기반의 parametrized heuristic rules(Turney, 1999)과 Naive Bayes learning scheme(Frank et al.,1999)입니다. 성능이 좋지 않기에 잘 쓰이지 않으며 후에 단어 표현(term representation) 과정 중 '언어적 지식'을 포함시켰을 때 성능 향상이 일어난(Hulth, 2003) 사례도 있었습니다.
(1) TextRank for Keyword Extraction
빈도 기준 핵심어 추출 성능이 좋지 않았으니 당연히(...) TextRank를 사용한 핵심어 추출이 더 성능이 좋다는 내용이 전개됩니다 :D
TextRank의 결과물은 단어, 구절 등의 집합입니다. 이들은 텍스트에서 추출된 하나 혹은 그 이상의 lexical unit sequence라 볼 수 있으며, vertex가 되어 그래프에 포함됩니다.
이렇게 정의된 vertex간 관계(relation)는 곧 두 개의 lexical unit간 관계로 간주할 수 있으며, edge로 표현됩니다. 여기서는 co-occurence 관계를 사용합니다. co-occurence는 lexical unit 들이 최대 N개 단어의 window 안에서 동시 출현할 때의 관계를 말하며 N은 2부터 10 사이의 수로 정의됩니다.
다만 모든 단어나 구가 vertex가 될 수 있는 것은 아닙니다. 모든 단위들을 포함하게 될 경우 그래프가 지나치게 커지기 떄문입니다. 따라서 Syntactic filter를 사용하여 한정된 vertex만이 그래프에 포함되게 만듭니다. 주로 명사-동사 혹은 명사-형용사만 필터링되도록 합니다.
(2) TextRank for Keyword Extraction 5단계
TextRank를 이용한 keyword extraction은 다음 5단계로 진행됩니다.
| 단계 | 내용 |
| 1. Text Tokenizing | 1) 형태소 태깅: syntactic filter적용을 위해 수행합니다 2) 그래프 추가 후보로 '단일 단어'만 고려 - 그래프가 지나치게 커지는 것을 피하기 위함 - post-processing 단계에서 multi-word keyword 재구성 |
| 2. Syntactic filtering | 1) 필터를 통과하는 모든 lexical unit은 그래프에 추가됨 2) lexical unit 간 edge 설정: N개 단어 window 안에서 동시출현 시 3) 각 vertex의 초기 score는 1로 지정 |
| 3. Ranking algorithm | 그래프에 대해 여러번의 iteration 진행 - 보통 20~30번의 iteration - convergence는 0.0001을 기준값으로 함 |
| 4. Sorting | 1) Score를 내림차순으로 정렬 2) post-processing을 위해 가장 높은 T개의 vertex를 유지함 - T는 임의의 고정값: 주로 5~20 사이 (해당 논문에서는 그래프 내 vertex 수의 1/3) - 텍스트 크기에 따라 키워드 수 결정 |
| 5. Post-processing | 인접한 키워드의 sequence가 multi-word 키워드가 될 수 있기에 이를 처리 |
이렇게 keyword extraction을 진행하면 아래 그림과 같이 나타낼 수 있습니다.
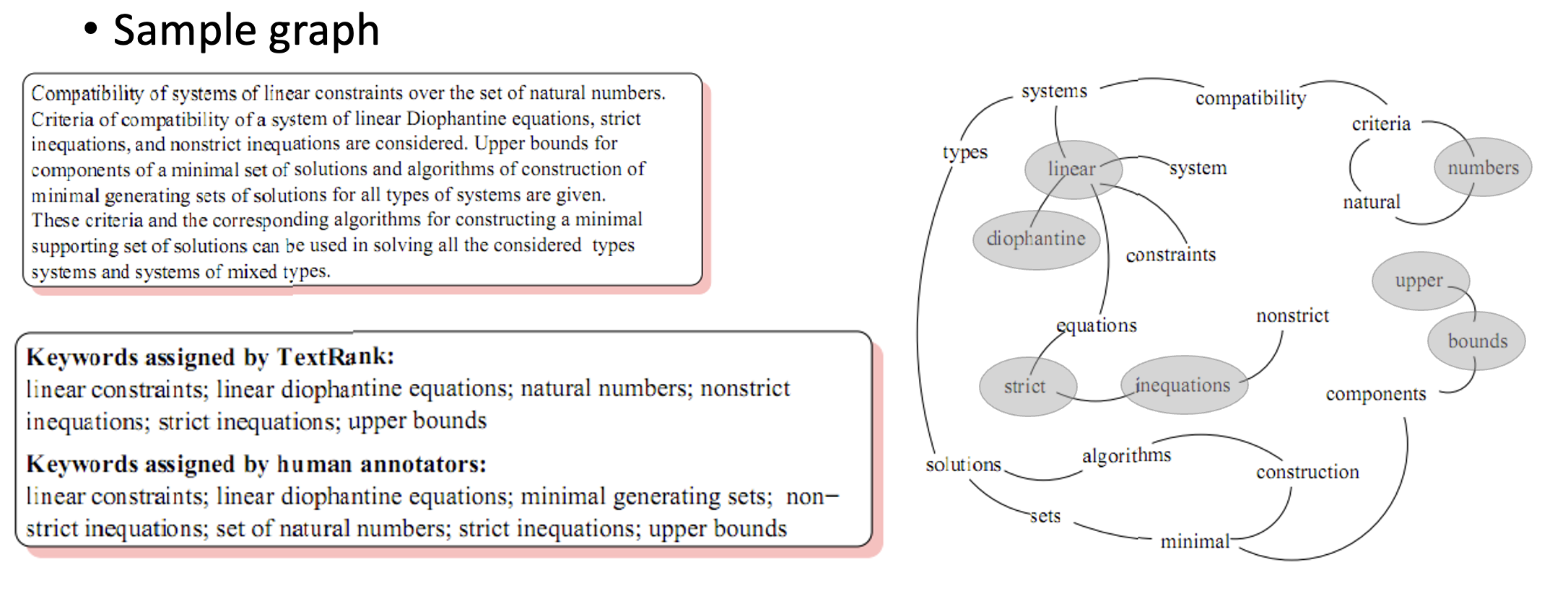
* 논문에서의 핵심어 추출 Evaluation
1. 대상: computer science and Information Technology 논문들 500개 초록
- 각 초록에는 두 개의 키워드 집합이 함께 존재: uncontrolled keyword 사용
2. 훈련&평가: TextRank: 비지도 기반 학습이므로 훈련/dev 데이터가 없음, 바로 test data 사용
3. 자동 핵심어 추출 결과: TextRank의 pre&f-score가 가장 높음
- 윈도우 사이즈 키우는 것은 도움이 없음: 멀리 떨어진 단어 간 관계는 강하지 않기 때문
- syntactic filter: 여러 필터 중 '명사-형용사'만 사용 시 가장 성능이 좋으며, 언어 정보는 핵심어 추출 과정에 기여도가 있음
4. TextRank를 사용한 핵심어 추출의 의의
- 이전 제안 방법보다 우수한 성능
- 완전한 비지도 학습: 텍스트 자체에서 유추한 정보만 사용하여 다르 문헌 집단, 도메인, 언어에 적용이 쉬움
4. TextRank for Sentence Extraction
이번에는 주요 문장 추출입니다. 이는 핵심어 추출과 마찬가지로 주어진 텍스트에 대해 더 높은 대표성을 지니는 sequence를 구별하는 task로, 핵심어 추출과 비교했을 때 unit을 sentence로 하는 것만 차이가 있습니다. 문장 추출의 의의는 모든 문장들을 순위화하고, 자동 요약 추출이 가능하도록 하는 것입니다.
문장 추출을 위한 그래프 생성은 vertex가 텍스트 내 문장이 됩니다. 핵심어 추출과 마찬가지로 관계를 따지는데, 이때 두 문장 사이에 '유사성'이 있는지 따져 연결을 판별합니다. '유사도(similarity)'에 대한 연산이 들어가며 두 문장 간 유사도 측정은 '내용이 겹치는 부분이 있는지'에 대한 함수로써 측정됩니다. 이는 문장은 단어에 비해 context를 가지고 있기 때문이고, 따라서 핵심어와 달리 co-occurence는 문장 추출에서 유의미한 관계 아닙니다. 이에 따라 문장 간 순서 상관 없이 유사한 내용이 있는 임의의 두 문장이라면 언제든지 edge가 형성될 수 있습니다.
문장에 대한 유사도 계산은 크게 2가지를 기반으로 할 수 있습니다. 하나는 두 문장의 lexical representation에서 비슷한 token들이 얼마나 겹치는지입니다. 다른 하나는 syntactic filter 사용을 통해 원하는 특성(ex. 명사, 동사, 형용사..)만을 대상으로 하는 계산입니다.
문장 유사도 계산에는 또한 normalize factor가 사용되는데, 이는 문장을 정규화하여 긴 문장을 더 많이 반영하는 것을 방지하는 장치입니다.

TextRank를 사용한 문장 추출을 진행하면 각 vertex간 edge에 가중치가 부여된, 매우 강하게 연결된 그래프가 리턴됩니다. edge의 가중치는 다양한 문장 쌍 간의 연결 강도를 의미하며 이를 계산하기 위해 그래프 기반 랭킹 formula가 적용됩니다. 핵심어 추출과 마찬가지로 문장 추출 역시 score를 기준으로 하여 내림차순으로 정렬합니다. 상위에 rank된 문장들은 요약문에도 포함할 수 있습니다.

* 논문에서 문장 추출에 대한 Evaluation
1. 대상: 단일 문서 요약을 위한 567개의 뉴스 기사, 목표는 TextRank를 통한 100어절 요약문 생성
2.평가: ROUGE score를 사용한 평가
- n-gram statistic 기반으로, 사람 평가와 높은 상관 관계를 지님(Lin and Hovy, 2003)
- 사람이 만든 2개의 reference 요약이 제공되며, 가장 높은 5개 시스템과 TextRank 성능 비교: 당연히 TextRank가 월등
3. TextRank를 사용한 문장 추출의 의의
- 사람이 수행하는 것과 유사한 요약 가능
- TextRank는 문장이 연결된 수도 평가하기에 중요 문장으로 선정 가능하며, 이는 사람의 문장 중요도 인식과 동일한 결과임
- TextRank는 텍스트 내 모든 문장에 ranking을 부여하므로 요약문 추출 시 쉽게 적용 가능
5. 결론
(1) 본 논문에서는 자연어 텍스트 처리를 위한 그래프 기반 랭킹 모델인 TextRank를 소개하였습니다.
(2) 또한 TextRank가 핵심어 추출, 문장 추출 task에서 뛰어난 성능을 지녔음을 보였습니다.
(3) TextRank의 장점은 높은 수준의 언어 지식, 도메인 지식, 그리고 해당 언어에 대한 주석 말뭉치를 필요로 하지 않는 것
- 이는 TextRank가 비지도 학습 기반이기 때문입니다.
(4) 또한 비지도 학습 기반 알고리즘이기에 다른 도메인, 장르, 언어에도 쉽게 적용될 수 있습니다.