토픽 모델링, LDA
*본 포스팅은 22-1학기 연세대학교 일반대학원 텍스트마이닝(송민 교수님) 수업을 정리한 것입니다.
1. 토픽 모델링 정의
토픽 모델링이란 구조화되지 않은 문헌집단에서 주제를 찾아내기 위한 알고리즘입니다. 여기서 쓰이는 '주제'란 같은 맥락에서 나타날 가능성이 있는 단어들의 그룹이라 할 수 있습니다. 이에 토픽모델링은 맥락과 관련된 단서들을 이용하여 유사한 의미를 가진 단어들을 클러스터링하여 주제를 추론하는 모델이며, 문헌 모델링, 문헌 집단 모델링이 가능합니다.
토픽모델링은 그러나 '문헌 내 용어 분포는 알 수 있으나, 주제들의 용어 분포는 사전에 알 수 없다'는 문제점이 있습니다. 이에 따라 문헌집단 내 문헌들의 용어 분포들로부터 주제 용어분포를 추정하는 과정이 필요한데, 이는 잠재 디리클레 할당(Latent Dirichlet Allocation:LDA)으로 가능합니다.
2. LDA(Latent Dirichlet Allocation)
LDA는 각 문헌은 주제가 무작위로 혼합되어 있으며, 각 단어는 해당 주제 중 하나에서 나온다를 가정합니다.
(1) LDA 이론적 배경: 베이즈 추론
LDA의 이론적 배경은 '베이즈 추론'입니다. 이 베이즈 추론에서 사용되는 분포 중 하나가 '디리클레 분포'이기 때문입니다. 디리클레 분포에서는 복잡한 확률 식 추정을 위해 '깁스 샘플링(Gibbs Sampling)'이라는 방법이 사용됩니다.
베이즈 추론은 정확한 확률 분포를 모르는 상황에서, 관측을 거쳐가며 확률 분포를 개선해나가는 모델입니다. 따라서 베이즈 추론을 사용하려면 일단 '1. 어떤 사건이 발생할 확률'을 가정합니다. 가정 후 2. 추가 관측이 발생하면, 이 3. 추가 관측된 사건을 통해 가정했던 사건이 발생활 확률을 더 정확하게 추론합니다. 이를 '사전 확률(prior probability; 선험적 확률), 관측, 사후 확률(posterior probability)이라는 3가지 개념으로 표현할 수 있습니다.
| 사전 확률 | 관측 없이 가정하는 특정 사건이 일어날 확률 |
| 관측 | 실제로 사건이 발생한 것 |
| 사후 확률 | 실제 관측된 사건을 가지고 해당 사건이 일어날 확률을 더 정확하게 계산한 것 |
1) 켤레 사전 분포(Conjugate Prior)
특정 관측 사건에 대해 사전 확률 분포를 적용할 경우 계산이 간편해지는데요, 이 사전 확률 분포를 켤레 사전 분포라 합니다.
| 가짓수 | 가능도 | 켤레 사전 분포 | |
| 가짓수 = 2일 때 | Bernoulli(베르누이 분포) A, B 둘 중 하나만 일어나는 사건 ex) 동전을 한번만 던지는 사건 |
Binomial(이항분포) A, B가 여러번 일어나는 사건 ex) 동전을 여러번 던지는 사건 |
Beta |
| 가짓수 > 2일 때 | Categorical(카테고리 분포) A, B, ..Z 중 하나만 일어나는 사건 ex) 주사위를 한번 던지는 사건 |
Multinomial(다항분포) A, B,...Z가 여러번 일어나는 사건 ex) 주사위를 여러번 던지는 사건 |
Dirichlet |
이항분포는 두 가지 중 하나가 발생하는 사건인데, 여러번 반복되면 binobial 분포이고 한번만 일어날 경우 베르누이 분포가 됩니다. 마찬가지로 다항 분포는 여러 개 중 하나가 발생하는 사건이 여러번 반복될 경우 multinomial 분포, 한번만 일어날 경우 카테고리 분포입니다.
i) 베타 분포: 이항 분포의 켤레 사전 분포
- 관측된 사건이 이항분포일 경우, 사전 확률을 베타 분포로 해야 사후 확률 계산이 쉬워집니다. 이는 복잡한 수식을 변화시키는 것보다 베. 타 분포의 하이퍼파라미터를 증감시킴으로써 사후확률분포 계산이 쉬워지기 때문입니다.
- 베타 분포의 하이퍼파라미터는 아래와 같이 2개입니다.
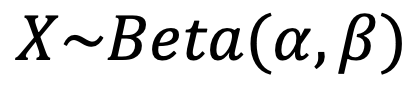
α = (A사건이 일어난 횟수 +1)
β = (B사건이 일어난 횟수 +1)
ii) 디리클레 분포: 다항 분포의 켤레 사전 분포
- 2가지 경우의 수만을 다루는 베타분포를 k 경우를 다루게 함으로써 확장시킬 수 있습니다. 디리클레 분포는 k가지 경우가 발생하는 사건에 대해 경우1이 α1-1번 나타날 확률은 p1, 경우2가 α2-1번 나타날 확률은 p2,... 경우k가 αk-1번 나타날 확률은 pk로 상정합니다.

- P는 p1,p2,…pk 의 확률값 벡터, α는 α1,α2,…αk의 하이퍼파라미터 벡터가 되며, 디리클레 분포의 하이퍼파라미터 α는 k개(α1, α2 ... αk)입니다. 이러한 디리클레 분포를 사용하면 여러 경우가 발생하는 사건을 관찰하면서 관찰 사건에 대한 경우 발생 확률 추정치를 더 좋게 개선시킬 수 있습니다. 즉 디리클레 분포는 다항분포의 사전 확률이며, 이를 활용하면 사후 확률 계산을 쉽게, 더 좋게 개선시킬 수 있습니다.
(2) LDA Topic Modeling
Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM, 55(4), 77-84.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
이 LDA를 사용하면 통계 분포를 통해 주제를 자동으로 찾는 토픽 모델링이 가능해집니다(Blei, D. M., Ng, A. Y., & Jordan, M. I. , 2003) 해당 논문에서의 가정은 다음과 같습니다.
| <LDA의 가정> 문헌은 여러 개의 주제를 포함할 수 있다 주제에는 여러 개의 단어가 포함될 수 있다 이에 따라 문헌에 사용된 단어 하나하나는 어떤 주제에 포함된다. |
또한 사람이 글을 쓰는 과정을 토대로 생성 모델(Generative Model)을 생각해볼 수도 있습니다.
| 1. 먼저 문헌에 어떤 주제들이 포함될지를 대략 구상한다 | 문헌의 주제 분포 결정 |
| 2. 주제들 중에서 하나를 고른다 | 주제 선정 |
| 3. 주제들에 포한된 단어들 중에서 하나를 고른다 | 단어 선정 |
| 4. 단어를 문헌에 추가하여 작성한다 | 문헌에 단어 추가(이 단어는 특정 주제의 것) |
| 2로 돌아가 다시 반복한다. | 반복하여 생성 |
앞서 설명한 베이즈 추론등을 고려하여 LDA를 사용한 토픽모델링을 다시금 정의하여보겠습니다.
1) LDA 토픽 모델링
단순한 토픽 모델링 시행 시 문헌 내 들어있는 단어들밖에 얻을 수가 없습니다. 즉 문헌의 주제분포 & 주제별 단어 분포를 알 수 없습니다. 이들을 알기 위해서는 관측 가능한 단어들로부터 잠재된(latent) 문헌별 주제 분포, 주제별 단어 분포를 추론하는 작업이 필요합니다.
만일 문헌에 주제가 k가지 있을 경우, k개 주제 중 하나를 고르는 것은 '다항분포'입니다. 또한 주제에 포함된 단어가 v개 있을 때, v개 단어 중 하나를 고르는 것 역시 '다항분포'이기에 다항분포 결과가 두 번 중첩되어 디리클레 분포를 사용하게 됩니다.
즉, 주제 분포&단어 분포는 베이즈 추론 중 다항 분포의 켤레 사전 분포인 디리클레 분포를 따르게 되고, 이를 통해 LDA 수행이 가능합니다. 정확하게 알지 못하는 주제 분포, 단어 분포의 확률 분포가 주어진 상황에서 단어에 대한 관측을 거쳐가며 이들의 확률 분포를 개선해나가는 것입니다.
| 사전 확률 | 관측 | 사후 확률 |
| 사건에 대해 미리 가정한 확률 | 사건의 관측 | 관측된 사건을 통한 확률 수정 |
| 문헌별 주제분포, 주제별 단어분포 가정 | 관측가능한 단어 | 주제분포, 단어분포의 확률분포 수정 |
디리클레 분포의 초기 하이퍼파라미터인 α는 문헌별 주제분포(θ)가 얼마나 밀집/희소한 지를 조절합니다. 주제별 단어분포(φ)도 디리클레 분포를 따르기에, 주제별 단어 분포의 하이퍼파라미터인 β는 주제별로 단어가 얼마나 밀집/희소한 지를 결정합니다.
보통 LDA 수행 시 사전에 결정하는 α, β, k 는 다음과 같습니다.
| α는 보통 0.1, β는 보통 0.0001로 부여 두 하이퍼파라미터의 값이 1에 가까워질수록 문헌에는 많은 주제, 주제에는 많은 단어가 포함됨 |
이외에도 문헌 내 존재하는 단어는 W, 얻고자 하는 문헌 내 주제는 Z라 가정하고 θ, φ는 각각 하이퍼파라미터 α, β를 따르는 문헌별 주제/주제별 단어 디리클레 분포라 가정하겠습니다. LDA는 문헌 내 W를 관측하면서, 이 단어들마다 적절한 주제를 부여하여 Z값을 정합니다. 이를 통해 θ, φ라는 디리클레 분포가 업데이트 되며, 가장 가능성이 높은 Z를 찾게 되면 문헌 내 단어들이 어떤 주제에 할당되어야하는지도 추론 가능합니다.
위의 과정을 베이즈 정리로 표현해보면 다음과 같습니다. LDA는 P(Z|W)를 최대로 하는 Z값을 찾는 것이 목표입니다. 이 때, W는 문헌 내 존재하는 단어 / Z는 단어가 배정된 주제 번호/ 위에서 P(W)는 Z와 관계 없는 상수이므로, P(Z|W)의 최댓값을 찾을 떄 고려하지 않아도 됩니다.

단어 관측 이전의 P(Z)는 순수한 주제 분포를 따릅니다. 이는 곧 문헌별 주제 분포인 θ과 관련이 있다는 뜻입니다. P(W|Z)는 특정 주제가 주어졌을 때, 해당 주제에 속한 단어가 나타날 확률이므로 주제별 단어 분포(φ)와 관련됩니다.
2) Gibbs Sampling
문헌 내 등장하는 모든 단어의 개수는 N입니다. 이에 따라 문헌 내 관측되는 단어 벡터 W, 그리고 단어들의 주제 벡터 Z도 모두 N차원 벡터로 맞추어지게 됩니다. 이 N차원 벡터가 주어졌을 때 확률(분포)을 계산해야 하는데, N이 점점 커질수록 계산이 기하급수적으로 어려워지게 됩니다. 이 N차원에 따른 계산 어려움을 해결하고자 깁스 샘플링이 사용됩니다.
깁스 샘플링에서는 N차원 자료 자체에 대해 확률 분포를 계산하기 보다는, 이를 1차원 자료 N개가 모인 것으로 가정하고 나머지 N-1개 자료를 고정시켜 1차원에 대해서만 자료를 샘플링합니다. 이렇게 각각의 자료를 샘플링하여 N개 합친 것은 결론적으로 N차원 자료를 샘플링한 것과 같아지게 됩니다.
위의 P(Z|W)를 깁스 샘플링으로 계산하면 아래와 같습니다.

이에 따라 문헌 d에 속하는 어떤 단어 m이 주제 j에 속할 확률은(=W가 주어졌을 때 Z가 등장할 확률), 주제 j에 속하는 모든 단어 중 단어 m이 차지하는 바중과 & 문헌 d에 속하는 모든 주제 중 주제 j가 차지하는 비중의 곱에 비례합니다. 깁스 샘플링을 사용한 LDA는 다음의 순서로 이루어집니다.
| 1. 각 단어에 임의의 주제 배정 |
| 2. (잘못됐겠지만^^;) 모든 단어에 주제가 배정된 상태 & 이에 따라 문헌별 주제 분포와 주제별 단어 분포가 결정됨 이것을 이제 깁스 샘플링으로 개선함 |
| 3. n번째 단어를 골라 빼냄(가정: 나머지 단어들은 모두 주제에 적절히 배정된 상태) |
| 4. 빼낸 n번째 단어를 제외, 나머지 n-1개의 개별 단어가 속한 문헌의 주제분포(P(Totic|Document) & 나머지 개별 단어가 속한 주제의 단어 분포(P(Word|Topic)) 계산 P(Word|Topic) * P(Topic|document)에서 Topic을 하나 뽑에 나머지 개별 단어에 배정 |
| 5. n ←n+1 후 다시 3번으로 감 |
| 6. 3~5를 반복하다보면 값이 수렴됨 & 단어들에 대해 올바르게 주제 배정 |
3) LDA의 문헌 생성 과정 알고리즘
위의 내용을 정리하는 느낌으로 다시 정리해보겠습니다. 우선 길이 N(=단어 개수가 총 N)인 문헌이 있다고 가정합니다.
i) N 선택하기
LDA의 문헌 생성 과정 첫 번째는 바로 이 N을 선택하는 것입니다. 이산확률분포(discrete probability distribution) 중 하나인 포아송 분포를 사용해 임의의 문헌 길이 N(=문헌 내 단어의 수 N)을 선택합니다.

ii) 디리클레 분포로부터 문헌별 주제분포 θ 선택
다음으로는 α를 하이퍼파라미터로 하는 디리클레 분포로부터 문헌별 주제 분포 θ를 선택합니다. α는 문헌 집단 내에서 정해지는 변수로, 학습을 통해 정해집니다.

iii) 문헌 생성
다음으로는 문헌을 생성합니다. 문헌을 생성할 때에는 (i) 어떤 문헌에 대한 주제 벡터 θ가 하이퍼파라미터일 때, 앞에서부터 단어를 하나씩 채울 때마다 θ로부터 하나의 주제(zn)을 선택합니다. 그 뒤로 (ii) 해당 주제 zn로부터 단어를 선택합니다.

여기까지의 과정을 그림으로 나타내보겠습니다.

깁스 샘플링은 LDA에서 문헌별 주제 분포와 주제별 단어 분포를 산출하기 위한 방법으로, 문헌 내 모든 단어 개수를 N이라 가정할 때 관측되는 단어 벡터 W & 단어들의 주제 벡터 Z는 모두 N차원 벡터가 됩니다. 이 N차원 벡터는 커질수록 기하급수적으로 복잡해지므로, 빠르고 쉽게 계산하기 위해 깁스 샘플링을 진행합니다.
이를 위해 저차원 분포에서의 반복적인 샘플링을 진행하여 고차원 분포와 유사한 수치들의 집합을 찾습니다. 구체적으로는 N차원 자료를 1차원 자료로 치환하여, 이 1차원 자료를 N개가 모인 것으로 간주하여 나머지 N-1개를 고정한 후에 1차원에 대해서만 자료를 샘플링하는 것입니다. 이러한 것을 N번 반복 후 합쳐버리면 결론적으로는 N차원 자료를 샘플링한 것과 같게 됩니다.
3. DMR(Dirichlet Multinomial Regression)
DMR(Mimno & Mccallum, 2008) 모형은 다항 토픽 모델링입니다. 이는 개체별 토픽의 추이를 분석하고자 제안되었으며 LDA 모델을 '과감히' 확장한 모형입니다 ^^
DMR은 문헌별 주제분포 하이퍼파라미터인 α가 그 문헌의 메타데이터(저자, 연도, 기관, 국가 등)에 따라 달라질 수 있음을 가정합니다. 이에 따라 α를 지배하는 자질 λ가 새로 추가되는데, λ는 평균이 μ고 표준 편차가 σ인 정규분포를 따르는 메타 데이터별 하이퍼파라미터 결정값입니다.

기존 LDA 그림과 거의 동일하나, 메타데이터 추가로 인해 관련 사항들이 늘어났습니다. 메타 데이터 x는 그의 개수인 F차원으로 원-핫 인코딩됩니다. 즉 메타 데이터 A, B, C 3개 존재 시 3차원으로 각각 (1,0,0) (0,1,0) (0,0,1) 표현된다는 뜻입니다.
DMR의 문헌 생성 과정은 크게 2가지입니다.
i) 주제별 메타 데이터 분포 및 단어 분포 선택

주제별 메타 데이터 λ와, 주제별 단어 분포인 φ를 뽑습니다. 모든 주제에 대해 위 과정을 반복하며, 이를 통해 주제별 메타 데이터 분포와 주제별 단어 분포를 생성합니다.
ii) 문헌 생성

앞서 생성한 λt를 사용하여 해당 문헌의 주제 분포를 결정할 α를 구합니다. 이 때 메타 데이터 벡터 x는 원-핫 인코딩 된 상태입니다. 따라서 이를 λt와 내적할 경우 해당 메타데이터가 속한 부분의 성분값이 도출됩니다. 이는 곧 문헌 메타데이터 별로 α가 바뀐다는 것을 의미하는데, 이는 α가 모든 문헌에 대해 같으면서 대칭적이었던 LDA와의 차이점이기도 합니다.
이를 문헌 내 모든 주제에 대해서 반복하면, 아래와 같이 해당 문헌의 주제 분포 하이퍼파라미터 θ를 구할 수 있습니다.

이렇게 메타 데이터에 의해 계산된 α에 따라 주제 분포 θ를 산출하고, 모든 단어에 대해 주제 분포에서 주제(z)를 하나 뽑고, 그 주제 안에서 단어(w)를 하나 뽑는 식으로 문헌이 생성됩니다.

| 1. 각각 단어에 임의의 주제를 배정 |
| 2. (잘못되었겠지만) 모든 단어에 주제가 배정됨. 그 결과 문헌별 주제 분포와 주제별 단어 분포가 결정되어, 이를 깁스 샘플링으로 개선 |
| 3. BFGS(Broyden-Fletcher-Goldfarb-Shanno)를 사용하여 현재 분포에 가장 적합한 λ를 찾음 - λ는 문헌별 주제 분포에 영향을 미치고, 또한 단어의 주제 z에도 영향을 준다 - 이 단어 주제 z에서 단어 w가 선정되어 w가 무엇인지 이 단계에서 알려진다. - 결론적으로 관측된 w와, w에 임의 배정된 z를 통해 가장 가능성이 높은(=확률을 최대로 하는) λ값이 도출된다. |
| 4. n번째 단어를 골라서 빼낸다. |
| 5. 빼낸 단어 외 나머지 개별 단어들이 속한 문헌의 주제 분포(P(Topic|Document)를 계산 & 나머지 개별 단어가 속한 주제별 단어 분포 P(Word|Topic)을 계산한다. 이후 P(Word|Topic) * P(Topic|Document)를 최대로 하는 Topic을 찾아 그 단어에 배정한다. |
| 6. n에 1을 더하고, 4번으로 돌아간다. |
| 7. 깁스 샘플링이 끝나면 3번으로 돌아가 다시 반복: 충분히 반복하면 값들이 수렴 & 안정된다. |
DMR을 충분히 수행할 경우 모든 단어들이 적절한 주제를 부여받게 되며, 이에 따라 문헌별 주제 분포, 주제별 단어 분포, 그리고
메타데이터별 최적의 하이퍼파라미터 λ를 얻을 수 있습니다.