12. LSTM(Long Short-Term Memory)
*본 게시물은 22-1학기 연세대학교 일반대학원 딥러닝을이용한비정형데이터분석(이상엽 교수님) 수업 내용을 정리한 것입니다.
앞선 포스팅에서 다루었던 RNN의 단점은 너무 멀리 떨어진 정보를 충분히 반영하지 못하는 장기 의존 문제(problem of long term dependency)였습니다. 이에 LSTM이 등장하게 됩니다.
| * 장기 의존 문제 - 입력된 문서에서 상대적으로 오래전에 사용된 단어의 정보가 잘 전달되지 않음 - 마지막 time step에서 생성된 히든 스테이트 벡터만 정달되는 경우, 문서 앞부분에서 사용된 단어들의 정보가 잘 반영되지 못한 상태가 됨 |
1. LSTM
Long Short-Term Memory라는 이름을 가진 LSTM은 RNN의 단점을 보완하기 위해 고안된 알고리즘입니다. 이전에 입력된 단어 정보를 더 잘 기억하기 위한 '기억셀(memory cell)'과 '게이트(gate)' 등을 활용하여 장기 의존 기억 문제를 해결합니다. 이와 비슷한 알고리즘으로는 GRU가 있습니다.
LSTM은 RNN과 유사한 원리로 작동합니다. time step t일 때, 입력으로 해당 차례 임베딩 벡터 xt와 이전 time step에서 넘어온 히든 스테이트 벡터 ht-1를 입력받습니다. 그러나 RNN달리 LSTM은 이전의 기억셀(ct)도 입력받아 오래전 단어 내용을 잘 기억할 수 있습니다. 또한 출력으로 히든 스테이트 벡터와 기억셀 벡터 이 2개를 리턴한다는 것도 특징입니다.
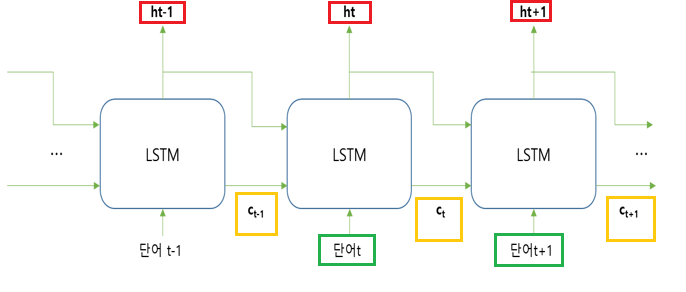
| LSTM 입력 | LSTM 출력 |
| 이전 히든 스테이트 벡터 해당 time step 단어 임베딩 이전 기억셀 정보 |
히든 스테이트 벡터 기억셀 정보 |
LSTM에서는 기억셀 원소 수(차원), 히든 스테이트 원소 수, 그리고 은닉 노드 노드 수는 모두 동일합니다.
2. LSTM 작동 원리
입력을 3개로 받고 출력을 2개로 한다는 간단한 원리에도 불구하고 실제로 자연어 처리 자료에서 LSTM을 표현한 것을 보면 매우 심란합니다(....)

수업에서는 교수님께서 매우 간단하게 도식화하여 보여주셨습니다. 일단 수업 자료에 따라 정리를 해보겠습니다.

일단 이 파란색 원 안에서는 다음 2가지 일이 일어납니다. 이 2가지 일은 뒤에 설명할 '게이트'를 바탕으로 이루어집니다.
| 1) 기억셀 ct 업데이트 | 이전 기억셀 ct-1이 이전 단계 히든 스테이트 벡터 ht-1과 단어 t의 임베딩 정보를 사용하여 ct로 업데이트 됩니다. |
| 2) 단어 t에 대한 히든 스테이트 ht 출력 | 단어 t의 임베딩 정보, ht-1, 그리고 ct의 정보를 사용하여 ht가 계산됩니다. |
● 게이트(gate)
게이트는 기억셀을 ct로 업데이트합니다. 즉 기억셀이 가진 이전 정보를 망각/기억하거나, 새로운 정보를 추가하여 기억셀을 업데이트 합니다. 이에 따라 task에 필요한 중요한 정보는 기억하고, 필요없는 정보는 망각할 수 있습니다. 또 훈련을 진행하다 task 수행에 중요한 정보가 나오면 기억할 수 있습니다. 이렇게 업데이트된 기억셀은 위에서도 설명했던 것처럼 새로운 히든 스테이트 벡터를 계산하는데 쓰입니다.
LSTM에는 서로 다른 역할을 하는 input, forget, output 게이트가 존재합니다. forget, input 게이트는 기억셀 벡터에서 정보를 삭제/추가하고, output 게이트는 새로운 히든 스테이트를 산출하는데 사용됩니다.
1) forget 게이트: ct-1에서 불필요 정보 삭제
이전 기억 셀(ct-1)이 가진 정보 중 정답 맞추기에 불필요한 정보는 삭제합니다.
ct-1이 가진 정보 중 몇 %를 망각할 것이냐를 결정하기 위해 이전 히든 스테이트인 ht-1, 단어t의 임베딩 벡터 xt, 그리고 [0,1]을 반환하는 sigmoid 함수를 사용하여 이를 계산합니다. 값이 0에 가까울 수록 더 많이 잊어버립니다.

기존 기억셀 ct-1에서 정보가 일정량 삭제된 ct-1'은 다음과 같이 표현됩니다. 저 돼지곱창같이 생긴 기호는 아미다르 곱하기로, 행렬곱 시 각 행렬별로 대응되는 원소 곱하기를 의미합니다.


2) input 게이트: ct-1'에 새로운 정보 추가 후 ct로 업데이트
일부 정보가 삭제된 ct-1'에 새로운 정보를 추가합니다. 추가 시에는 이전 히든 스테이트 ht-1과 단어 t 정보를 사용하여 계산을 하게 되는데, 이때는 추가되는 정보가 얼마나 긍정적인지 부정적인지 나타내기 위해 범위를 [-1, 1]로 가지는 tanh()을 이용합니다.
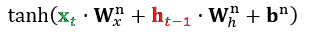
다만 하이퍼볼릭탄젠트 함수 결과가 그대로 반영되는 것은 아닙니다. 정답에 기여하는 정도에 따라 비율을 다르게 산정하기 때문입니다. 이때는 다시 [0,1]을 범위로 하는 sigmoid 함수를 사용합니다.

이렇게 forget 게이트로 기존 기억셀 ct-1에 존재하는 불필요한 정보를 삭제하고, input 게이트로 정답 맞추기에 필요한 정보를 다시 추가하는 과정이 끝났습니다. 최종적으로는 다음 수식과 같이 표현하며, 그림으로는 아래와 같이 표현할 수 있습니다.


3) output 게이트: ct를 사용하여 히든스테이트 ht를 계산
ht는 현재 LSTM 층에서 출력되어야 하는 값입니다. 이에 따라 1)~2)를 거쳐 업데이트된 기억셀 벡터 ct값을 조정하여 ht를 구합니다.
이를 위해서는 먼저 ct에 tanh을 적용하여 ct의 긍부정 역할을 밝혀야 합니다. 이후 ct가 가진 원소들 중 정답에 기여하는 정도를 반영하기 위해 sigmoid와, ht-1, 그리고 단어 t의 임베딩 벡터 정보를 사용합니다. 이 두가지 결과는 아마다르 곱으로 계산됩니다.


이와 같이 LSTM에서 기억셀 ct, 히든 스테이트 ht 업데이트가 끝났습니다. 주의할 점은 기억셀은 다음 계층으로 값이 전달되는 것은 아닙니다. LSTM 층 내에서만 이전 단어 정보 기억 목적으로 사용하게 되며, 다음층으로 전달되는 값은 히든스테이트 ht뿐입니다.
전반적인 LSTM의 작동 순서는 다음과 같습니다
| 기억셀 ct-1에서 불필요 정보 삭제 | forget 게이트 |
| 정보가 삭제된 기억셀 ct-1'을 ct로 업데이트 | input 게이트 |
| ct를 사용하여 ht-1를 ht로 업데이트 | output 게이트 |
3. bi-LSTM
이전까지의 LSTM은 한 방향으로 작동했습니다. 즉 이전 단어의 정보만 사용했었습니다. 그러나 그 다음 단어 정보가 중요하거나, 혹은 역순으로 읽을 때 추출하지 못하는 정보를 추출할 수 있습니다. 이때 bi-LSTM을 사용하여 역방향 작동을 함으로써 양방향으로 문서의 정보를 참조할 수 있습니다.
양방향에서 알 수 있듯이 방향이 서로 다른 LSTM을 사용합니다. 순방향은 기존 LSTM과 같으며 마지막에는 히든 스테이트 벡터가 리턴됩니다. 이때 기억셀 정보는 그 다음 층으로 전달되지는 않습니다.
역방향은 시퀀스 데이터 중 마지막 단어부터 입력합니다. 즉 마지막 히든스테이트를 받아서 전달하며, 전달 시 concatenate를 사용합니다. 따라서 히든스테이트 벡터 원소 수가 j일 경우 2j가 전달되는 식이며, 이 콘캣된 결과가 소프트맥스로 갑니다.

4. GRU(Gated Recurrent Unit)
GRU는 LSTM과 마찬가지로 장기 의존 문제를 해결하기 위해 만들어진 알고리즘이며, 역시 마찬가지로 게이트를 사용합니다. 단 게이트는 reset 게이트와 update 게이트 2개만 사용하여 히든 스테이트를 업데이트하고 기억셀을 사용하지 않습니다.
GRU는 LSTM보다 간단한 구조를 가지고 있어 속도는 빠르나, 정확도는 떨어지는 단점이 있습니다. 이에 따라 텍스트 길이가 비교적 짧을 때 사용하는 것이 좋습니다.
