R통계특강 3
*본 글은 " 2022 한말 온라인학교 국어학과 한국어 교육자를 위한 R을 활용한 통계의 쌩기초" 내용을 정리한 것입니다.
<통계특강 2 recap>
- 표본의 특징을 요약해서 보여주는 방법: 중심경향성, 변동성 척도
- 중심경향성: 평균(mean), 중간값(median), 최빈값(mode)로 표본 요약 가능
- 평균의 문제점: 이상값이 있으면 쓸 수 없음
- 최빈값: 수치형이 아닌 범주형일 때 적용
1. 변동성 척도(measure of variability)
● 변동성 척도의 정의
- 표본/모집단을 요약해서 보여주는 특징, 평균을 중심으로 모여있는지 퍼져있는지를 봄
즉 통계 자료의 변동 정도가 얼마나 되는지 나타내는 방법
- 퍼짐 척도(measure of spread): 자료가 퍼져있는 정도
ex. 범위, 사분위간 범위, 분산(&자유도), 표준편차(정규분포, t분포, F분포...)
(1) 범위(range)
- 최솟값에서 최댓값까지의 거리(범위 = 최댓값 - 최솟값)
BUT 평균처럼 범위에서도 최댓값 & 최솟값이 전부 이상값일 때 자료의 퍼짐 정도를 잘 나타낼 수가 없음
→ 사분위수 범위 사용
(2) 사분위수 범위(interquartile range): 범위에 의한 변동성 척도가 이상값에 의해 왜곡될 경우 사용
- 전체 표본을 늘어놓고 4개로 등분할 때 등분한 경계에 해당하는 값들
- Q3-Q1만 사분위수 범위(interquartile range)로 인정하여 왜곡을 피함
- 일사분위수(Q1, first Quartile): 1/4, 25%의 값
- 이사분위수(Q2, second Quartile): 2/4, 50%의 값 = 중간값
- 삼사분위수(Q3, third Quartile): 3/4, 75%의 값
- 사분위수 범위(interquartile range): Q3 - Q1

- box plot으로 표현 가능

(3) 분산(variance)과 표준편차(standard deviation, sd)
1) 분산: 모든 자료가 평균으로부터 떨어져 있는 거리를 제곱한 것의 평균값(편차제곱합/분모)
※ 모분산은 분모가 n, 표본분산은 분모가 n-1

ex) 강사별 친구 수
강사1: 친구 1명 강사2: 친구 2명 강사3: 친구 3명 강사4: 친구 3명 강사5: 친구 4명
평균: 2.6명 & 강사들의 표본이므로 표본분산 사용
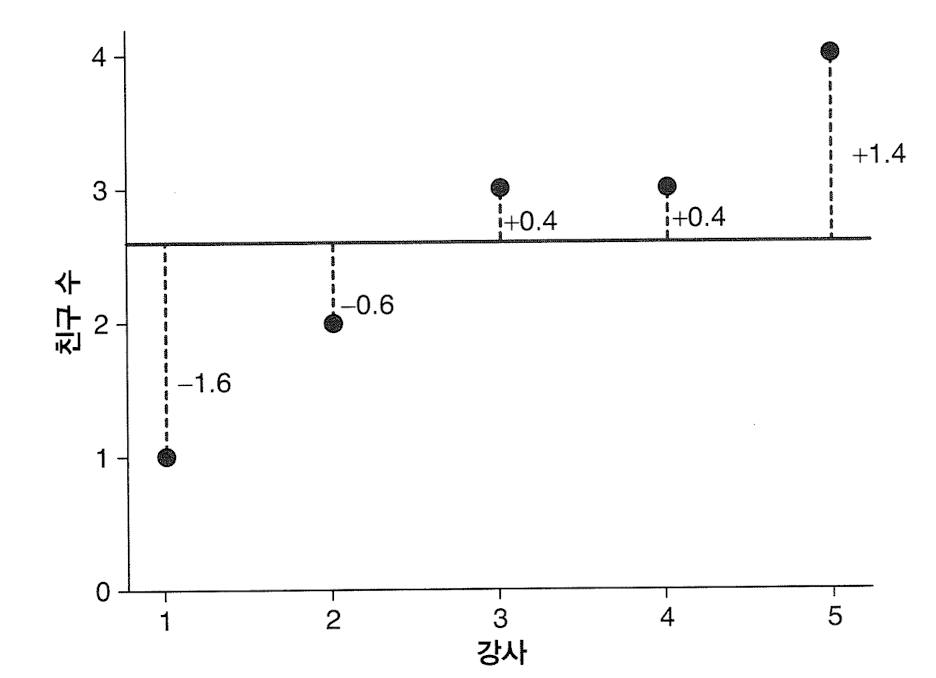

2) 표준편차(standard deviation, sd): 분산의 제곱근

2. 표와 그래프
● 기술통계 vs 추론통계
- 기술 통계: 표본에 대한 표와 그래프, 수치에 의해 서술 & 기술하는 것
- 추론통계: 표본을 통해 모집단에 대해 추론해내는 것
⇒ 통계는 주로 기술통계보다는 추론통계를 이야기함
- t검정, 분산분석, 회귀분석...: 모집단 특성을 추정하기 위한 통계 기법
| recap) 1강의 1. 기술 통계(descriptive statistics)와 추론 통계(inferential statistics) (1) 기술 통계: 표본을 기술하는 통계 - 기술 통계의 측정치 = 통계량(statistic), 표본의 측정치라고도 불림 - 전수조사 : 모집단 전체를 조사함 (2) 추론 통계: 표본에 기초하여 모집단을 추론하는 통계 - 추론 통계의 측정치 = 모수치(parameter), 모수가 가진 통계치/측정치 - 표본 조사: 모집단이 너무 클 경우 표본을 표집해서 조사함 표본을 구하는 방법: 대표성, 균형성 중심 |
● 기술통계를 요약하는 방법
- 수치를 통해(평균, 중간값, 사분위수...) / 표 / 그래프 등이 있음
: 표 기술통계(tabular descriptive statistics)
: 그래프 기술통계(graphical descriptive statistics)
: 수치 기술통계(numeral descriptive statistics)
- 그럼 그래프는 왜 그리는가????
: 자료를 실제로 분석하기 전 자료를 전체적으로 살펴보는 것이 필요
: 자료를 시각적으로 표현하여 파악 후 좀 더 중요한 통계량을 해석하는 것이 중요
(1) 도수분포표(frequency table)
- 표본에 대해 통계를 낸 것은 다 도수분포표로 표현 가능함(단, 변수가 하나일 때만 가능)
- 범주형 자료 & 숫자형 자료에 적용
- 숫자형 자료에 적용 시 계급(class)으로 우선 나눔: 계급 구간(class interval), 계급폭을 사용해 계급 구성
- 상대도수분포표: 도수(빈도, frequency)를 전체 자료 수(n)로 나누어 비율로 나타낸 것, 전체는 1

(2) 막대 그림(bar chart)과 파이그림
- 명목형 자료를 그래프로 기술할 때 사용

(3) 히스토그램
1) 정의: 숫자형 자료(양적 자료: 등간, 비율척도)를 도수분포표를 이용하여 그래프로 나타냄
※ 숫자형 자료 <-> 범주형 자료(명목, 서열척도)

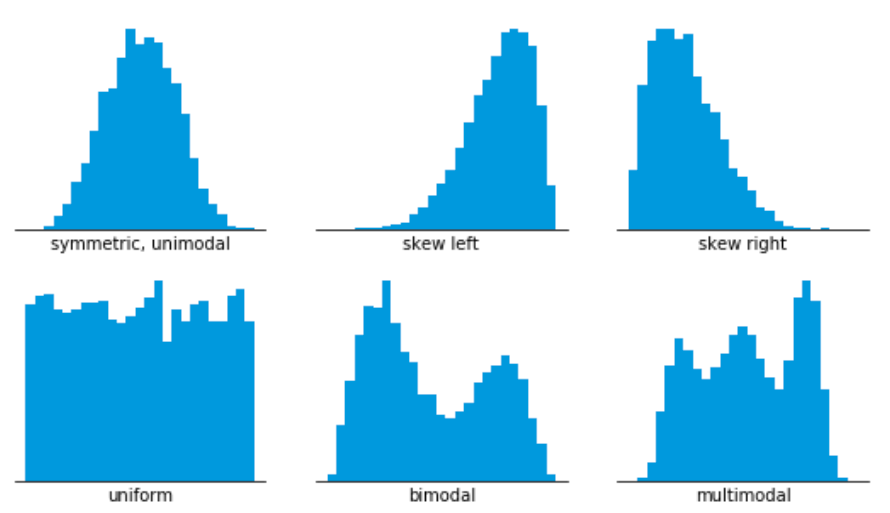
- 히스토그램에서 중요한 정보는 왜도(skewness)와 첨도(kurtosis)
2) 왜도(skewness): 어느 방향으로 얼만큼 쏠려있는지를 보는 것
mean이 가운데에 위치하고, mean = mode일 시 왜도는 0
양의 왜도(positive skewness): 최빈값이 평균보다 왼쪽에 있을 때
- 왼쪽으로 크게 있으면서 오른쪽으로 길게 늘어진 모양을 가짐
음의 왜도(negative skewness): 최빈값이 평균보다 오른쪽에 있을 때
- 오른쪽으로 크게 있으면서 왼쪽으로 길게 늘어진 모양을 가짐

3) 첨도(kurtosis): 확률분포 꼬리가 두꺼운 정도
- 보통 봉우리 높이를 이야기하기도 함: 봉우리가 낮으면 꼬리가 두껍고, 봉우리가 높으면 꼬리가 얇아짐
- 극단적 편차 혹은 이상값이 많을수록 큰 값을 나타냄

(4) 상자 그림(Box plot)
다섯 숫자 요약: 최소값, 일사분위수, 중간값, 심사분위수, 최대값
그래프로 그린 것: 상자수염그림(box-and-whisker plot) 혹은 상자 그림(box plot)

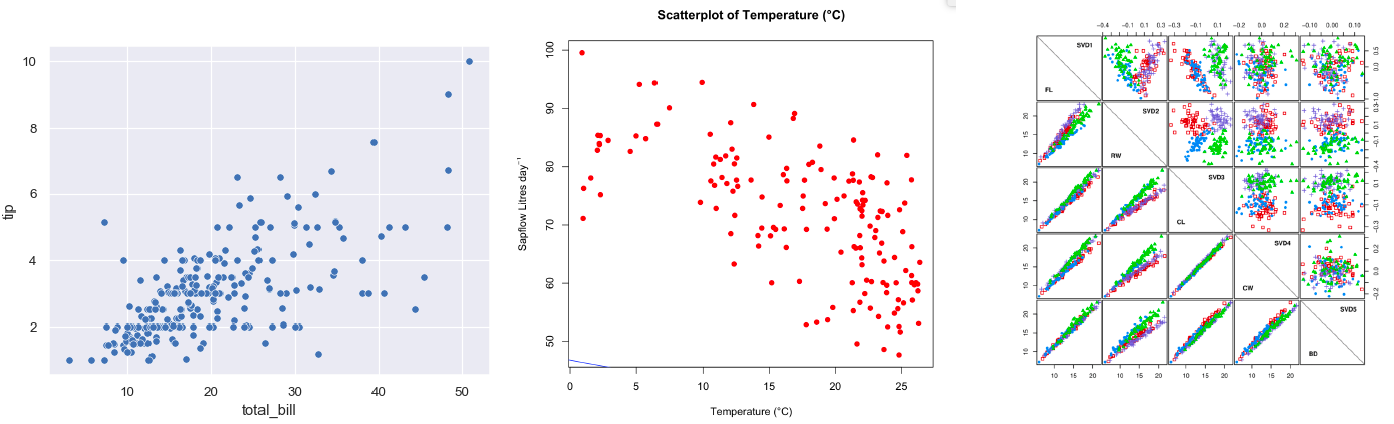
(5) 산점도 (Scatter plot)
짝으로 되어 있는 두 개의 자료를 나타낼 때 사용
① 양의 선형 관계: 점들이 왼쪾 밑에서 오른쪽 위로의 방향으로 나열된 경우
② 음의 선형 관계: 왼쪽 위에서 오른쪽 아래 방향으로 나열되어 있는 경우
③ 산점도 행렬(scatter plot matrix): 3개 이상의 변수 조합 시 가능
- 각각 따로 그려진 여러 산점도를 동시에 보면서 전체적으로 변수들 상호간 관계 파악
(6) 분할표(Contingency table)
둘 이상 변수가 명목형 자료 또는 순서형 자료라면 이 자료들에 대한 이차원 또는 다차원 형태의 도수분포표를 만들어 놓은 것

(7) 이상값(Outlier)
자료에서 다른 값에 비해 특이하게 아주 크거나 아주 작은 값
이상값 발견 시 입력상 오류인지 확인, 입력상 오류가 아니라면 분석에서 제외
| 단, 제외 시에는 신중해야 함 이상값을 넣은 통계와 뺀 통계를 동시에 제시하고, 어느 쪽에 얼마나 비중을 두어야 하는지 분석자의 판단을 같이 보고하는 것도 좋음 |
3. 정규분포와 표준화
(1) 확률 분포?
● 확률 변수(random variable): 확률 실험에서 나타날 수 있는 모든 결과에 대해 수치를 부여한 것
● 확률 분포(random distribution): 한 변수가 어떤 실험이나 관찰의 결과로 나타날 수 있는 모든 상황과, 각 상황이 나타날 확률을 표현한 것
① 이산 확률 분포(discrete probability distribution)
확률변수가 수량변수 중에서 이산변수(discrete variable; 두 값 사이에 셀 수 있는 수의 값이 있는 숫자 변수)인 경우
ex) 동전을 던질 때 앞면의 횟수, 주사위를 던질 때 3이 나오는 횟수

② 연속 확률 분포(continuous probability distribution)
연속변수인 경우에 나타나는 분포 ex) 자동차 속도, 고등학생의 키

(2) 정규분포(Normal distribution)
평균이 μ이고 표준편차가 σ인 정규분포 안에서 특정 점수가 발생할 확률
표본을 통한 통계적 추정 및 가설검증이론의 기본이 되는 분포
정규분포의 특성: ① 연속형 변인, ②좌우 대칭의 단봉 분포, ③정규 곡선과 X축 사이 면적은 1, ④ 분포의 특징 N(μ, σ²)

d
d
d