R통계특강2
*본 글은 " 2022 한말 온라인학교 국어학과 한국어 교육자를 위한 R을 활용한 통계의 쌩기초" 내용을 정리한 것입니다.
1. 변인과 측정 척도
1. 측정과 변인의 정의
측정(measurement): 물체의 어떤 특성에 대해 일관성 있게 숫자를 부여하거나 구분하는 것
변인(variable): 연구자가 관심을 가지는 연구 대상 속성, =변수
2. 변인
가설 검증을 위해서는 변인 측정이 필요함. 이때 변인은 독립변인과 종속 변인으로 나누어짐
(1) 독립변인(independent variable): 원인으로 제시된 변인, =원인이 되는 것, =예측변인
(2) 종속변인(dependent variable)L 결과(효과)로 제시된 변수, =결과가 되는 것, =결과변인
3. 측정수준
측정수준: 측정대상과 측정 대상 수치와의 관계, =측정 척도(scale of measurement)
(1) 범주형 변인(categorical variable): 정해진 범주 중 하나의 값으로 측정
사칙연산이 불가능한 변인들
1) 명목 변인(nominal variable): 이름, 문자로 나타나며 순서가 없음
ex) 펜, 연필, 지우개 / 남자, 여자 등...
2) 서열 변인(ordinal variable): 이름, 문자로 나타나며 순서가 존재함
ex) 리커트 척도 / 좋음, 보통, 나쁨/ 초, 중, 고
(2) 연속형 변인(continuous variable): 사칙연산이 가능, 숫자형 자료
1) 등간 변인(interval variable): 배율을 사용할 수 없는 경우
ex) 2a ≠ b, 20도의 2배 ≠40도, 섭씨 0도는 온도가 없는 것(X)
2) 비율 변인(ratio variable): 비율을 사용할 수 있는 경우
(3) 통계에서의 의미
단, 통계에서 등간변인, 비율변인은 크게 구분하지 않음
통계에서 유의미한 변인: 명목변인(척도), 순서변인, 연속형 변인 3가지
단, 언어학에서는 명목변인 / 순서변인 & 연속형 변인으로 처리하기도 함 (둘을 구분하기가 힘들기 때문에)
순서 변인을 다룰 때에는 연속현 변인의 통계 기법을 사용할 수도 있음
-특히 언어학 연구의 경우 리커트 척도 사용 시 순서변인 통계기법으로 처리가 어려울 때가 있음
연속형 통계 기법을 대신 사용함
4. 시계열 자료, 횡단면 자료
(1) 시계열 자료(time series data): 시간 변화에 따라 얻는 자료
(2) 횡단면 자료(cross-sectional data): 동시간대에 얻는 자료
5. 집중경향성과 분산도
(1) 집중경향성(central tendency): 자료의 전반적인 수준을 나타내는 지수, =대표값
-평균(mean), 중간값(median), 최빈값(mode) 존재
1) 평균: 모든 자료의 값을 다 더한 후 전채의 개수로 나눈 값
-집중경향성을 가장 잘 나타내며 산술평균(methematical mean)이라고도 불림
-모평균(population mean), 표본평균(sample mean) 존재

-단, 이상값(=특잇값, 이상치, outlier) 존재 시 부적절한 방법: 이 때는 중간값 사용
2) 중간값: =중앙값, 중위수; 이상값에 영향받지 않고 사용할 수 있는 중심경향성
-자료를 크기 순으로 늘어놓았을 때 가운데에 해당하는 값
-중간값은 홀수/짝수냐에 따라 구하는 방법이 달라짐
| n이 홀수 | (n+1)/2 번째 크기순 자료 |
| n이 짝수 | 가운데 있는 두 개 값의 가운데 값 |
3) 최빈값: 자료 중에서 그 빈도수가 최대인 값
- 명목형 자료의 경우 평균, 중간값의 의미가 없음
ex) 옷들 중에서 유행하는 것 = 빈도가 높은 것, 유행에 대해서는 평균, 중간값을 매길 수 없음
- 다만 자료의 수가 너무 적을 때에는 무의미하며, 최빈값은 여러 개가 될 수 있음
4) 사분위(Quartile) 수(구하기 어려움)
자료를 크기순으로 늘어놓은 후 똑같은 크기의 네 덩어리로 만들 때, 그 경계에 해당하는 값
사분위수는 box plot으로 표현 가능
① 일사분위수(Q1): 1/4, 25%의 값
② 이사분위수(Q2): 2/4, 50%의 값 =중간값
③ 삼사분위수(Q3): 3/4, 75%의 값
④ 사분위간 범위(interquartile range): Q3-Q1
※ 사분위수 구하는 법
i. 오름차순으로 데이터값 배열
ii. 중간값(Q2) 찾기
iii. 아래에서 중간값 찾기(Q1)
iv. 윗쪽에서 중간값 찾기(Q3)
(2) 분산도(dispersion): 자료들이 대표값을 중심으로 흩어진 정도
-범위(range), 사분위수범위(interquartile range), 사분위편차(quartile deviation), 표준편차(standard deviation),
분산(variance, =변량)
※ 변동성 척도(measure of variability): 특히 사분위수로 파악하는 것이 가능
-변동성 척도는 통계 자료가 변동하는 정도가 얼마나 되는지를 나타내는 방법
- 퍼짐척도(measure of spread): 자료가 퍼져있는 정도
-범위, 사분위수범위, 분산, 표준편차 등등이 속함
1) 범위(range)
최솟값에서 최댓값까지의 거리(범위 = 최댓값 - 최솟값)로 이상치를 제외하여 볼 수 있는 방법
2) 사분위간 범위(interquartile range)
범위에 의한 변동성 척도가 이상값에 의해 왜곡될 때에는 사용
3) 분산과 표준편차
① 분산(variance): 모든 자료가 평균으로부터 떨어져있는 거리를 제곱한 것의 평균값, 모분산과 표본분산 존재
i. 모분산: n은 숫자
ii. 표본분산: n-1 사용(자유도)
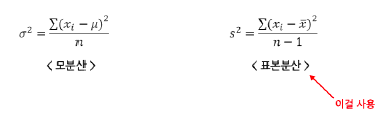
② 표준편차(standard deviation): 분산의 제곱근
4) 자유도(degree of freedom; DF)란?
- 자유도를 기반으로 해서 t분포, f검정 등을 사용
- 표본 기초 시 자유도를 반드시 기반으로 해야 함
- 자유도는 임의로 변할 수 있는 관측들의 계수와 관련
- 모집단의 표준편차를 구하기 위해서는 표본의 평균을 모집단의 평균에 대한 추정값으로 사용
- 표준편차나 분산의 경우에는 모분산, 모평균을 추정한 것이기에 자유도 개념이 도출된 것
- 모분산과 관련된 것은 그리스 문자, 표본과 관련된 것은 영어 알파벳